零基础实现高质量数据挖掘(数据分析篇)
/title2.jpg)
1 简介
1.1 上手难度
目前“零基础”解决方案是不需要学习太多python语法的,基本上是类似“命令行”的参数化解决方案,全部需要写的可能也几句代码来形成一份通用的“配置文件”,运行后实现所有分析内容自动写入报告后输出,虽然说起来要写代码却基本上能实现“零基础”入门,
从历史培训实践来看,基本没有学习难度,小白也能快速上手,投入产出非常惊人,具体案例在本章的最后一节1.4 案例展示中会进行演示
1.2 业界对比
针对以上问题,按市场行情和业界实践,这里按类别梳理了对比的表格:
| 平台类解决方案(PXX平台、图X平台等) | 单机商用解决方案(SXX/SXXX等) | 直接使用开源模块(c/c++/python/java/r等) | 我的解决方案(基于开源模块二次开发与封装) | |
|---|---|---|---|---|
| 价格 | 高,主要面向企业用户 | 中,部分面向个人用户 | 无,开源 | 低,主要面向个人用户 |
| 操作难度 | 低,面向非编程人员,主要使用点击和拖拉拽 | 中,可使用点击和拖拉拽,或自定义脚本开发 | 高,主要面向编程人员,直接撰写代码需要控制大量细节 | 中,参数化封装配置文件,可融合自定义脚本开发 |
| 分析颗粒度 | 粗糙,基于组件封装不可进行细节调整,部分平台能支持较为细致的代码融合开发 | 一般,页面点击或脚本自定义 | 细致,基于源代码开发 | 细致,模块化参数控制或基于源代码开发 |
| 开发成本 | 中,拖拉拽点击配置,一般可加载复用,如涉及脚本自定义开发则开发成本较高 | 中,拖拉拽点击配置,一般可加载复用,如涉及脚本自定义开发则开发成本较高 | 高,debug开发成本不可控制,且不同场景通用性较低 | 低,参数化封装后,配置文件一次配置可多次重复使用 |
| 硬件要求 | 高,一般需要服务器部署配置各类服务项 | 中,一般单机点击安装包即可 | 低,基于源代码任意安装和开发 | 中,单机安装conda/python配合pip即可 |
| 一体化程度 | 高,通常能同时支持特征生成和模型部署等全流程操作 | 中,一般不包含特征工程,可导出模型文件和分析结果 | 低,基于源代码自行开发 | 中,不包含特征生成,针对分析本身,导出对应的模型文件和分析结果 |
| 扩展性 | 低,一体化平台一般不支持非官方自定义扩展 | 中,不支持扩展或官方插件扩建需要加钱,或只能使用特定脚本扩展 | 高,可基于任意生态任意扩展融合 | 高,可基于python生态任意扩展融合 |
我的解决方案非常适用于以下几类场景:
- 我既不想写代码,也不会写代码,我就想知道数据效果怎么样
- 按规矩的方式仔细做分析要好久,我想知道有没有深入分析的必要性
- 重头到尾整合报告太累了,我需要一个工具一键生成常见的报告
- 代码我都会写,原理我也都懂,只是现在没时间慢慢搞
- 学过一遍之后剩下的都是重复操作,我想避免无意义的内卷,留点时间干别的
简单总结来说,我的解决方案可以在较低的开销下,参数化模块化常用分析结果,帮助分析师绕开繁琐重复的日常操作,可快速生成分析结果并反复参数化调优,在维持高质量分析的基础上大幅降低分析成本
1.3 数据适用性
如果是数据量足够大的情况下(PB起步,淘宝、微信,或流水日志等等),一般也没有太多可以选择的空间,基本都是各类hdfs分布式数据库进行存储和操作,例如阿里的odps、常见的hive\hadoop\spark套件等等,这个维度也不是各类单机分析软件的处理领域,
从业界实践来看,一般很多分析确实没有那么大的数据量,即使数据量真的很大,在具体设计方案上和实施层面中也有很多解决的办法和优化的方式,举例如下:
- 从统计学抽样方式进行数据切片并将一次任务转化为多次进行数据降维
- 较为严格的在时间层面上定义观察期和表现期来缩小可用数据范围
- 较好的进行前置分析,对数据进行合理的预分群等进行样本拆分
- 前置spark等分析工具预处理降低后期细颗粒度分析时的数据宽度
- 实现内嵌spark等底层分布式解决方案,如xgboost和lightgbm等
- 直接基于分布式服务器环境搭建jupyterhub等工具,内存理论上无上限
1.4 案例展示
目前整体由三个模块构成,分别处理不同类型的问题,本文聚焦的“数据分析”模块主要面对分类问题,在金融风控等领域非常常见,先来看一个简单的实战案例,
首先需要配置一个python环境,可以参考:jupyter环境搭建、python环境管理,数据集方面使用了Kaggle的Credit Card Approval Prediction的数据,需要登录下载或直接使用我下载的数据文件,所需的python分析代码如下:
import pandas as pd
# 导入我自定义的模块
import sys
sys.path.append("/home/conda_env/code_libs")
import alpha_tools as at
# 导入数据
df_ = pd.read_csv("application_record.csv")
df_response = pd.read_csv("credit_record.csv")
# 添加“年龄”变量
df_['Age'] = -(df_['DAYS_BIRTH']) // 365
# 定义标签和数据
df_["target"] = df_["ID"].map(df_response.groupby("ID")["STATUS"].apply(
lambda x: 1 if ({"2", "3", "4", "5"} & set(x)) else 2 if ({"1"} & set(x)) else 0))
df_data = df_[df_["target"].notnull()]
# 划分数据集
from sklearn.model_selection import train_test_split
df_train, df_test = train_test_split(
df_data, test_size=0.3, stratify=df_data["target"], random_state=42)
# 进行分析
at.Analysis.data_flow(df_train, "./数据分析demo/v1/v1.xlsx", test_data=df_test, response="target")这样就完成了初步分析,分析过程视频如下:
可以点击下载来查看分析报告:数据分析报告v1.xlsx,里面包含了各类变量分析和数据预览,目录如下:

参数化配置类比后端输入,Excel报告展示类比前端输出,本文后面几个部分会分模块对参数和报告内容进行逐项拆解,并介绍如何进行调参完成数据分析全过程
2 基础定义
数据挖掘子模块实在太多了,按建模目标可以分为:分类、回归、聚类问题,按主题还可以分为:营销、风控、欺诈、图像识别、文本翻译、自然语言处理,而其中的分类也可以有二分类、多分类,不同的主题有不同的分析链路和分析范式,如果没有领域志向,很难把分析元素固定和泛化,从上面的案例也可以看到,本文涉及的参数化工具包主要是针对二分类问题的,业界常用的场景有金融领域的风险识别、营销响应、欺诈识别等等,这里都按风险识别进行举例
2.1 数据定义
主要需要定义的必填项是train_data和output_name参数,其他参数包括test_data等全都是选填项,
# 必填项
# train_data 必填,训练集,pd.DataFrame数据类型
# output_name 必填,绑定的各类输出的基本名称,需要以.xlsx结尾除了必填项目,还有一些常见的可选参数,
# 基础定义
# nan_group 选填,默认"missing",缺失值对应的填充项
# test_data 选填,默认None,对应的测试数据或验证数据
# task_type 选填,默认"binary",任务类型,目前不可修改
# exclude_column 选填,默认None,排除的数据的列,支持str和list
# sample_weight_name 选填,默认None,输入后来指定使用某一列的数值调整样本权重上述参数构成了较为基本的数据定义,包括数据排除、数据集定义、数据权重设置、数据类型校准等,一般二分类任务常见会进行数据分箱计算woe/iv等,目前这个模块的task_type只支持"binary",
在涉及到缺失值处理时,我在进行处理时默认会将缺失值设置为单独一组并在报告中展示nan_group为"missing",如果确实有填充需求可以提前使用pandas的fillna单独提前处理,或使用下一节2.2 数据预处理介绍的replace_option来进行处理
2.2 数据预处理
# 基础定义
# replace_option 选填,默认None,{"num_replace"/"dis_replace:{key:value}}
# auto_convert_dtype 选填,默认True,将train_data和test_data每列数据类型转化一致
# 极端值处理相关
# enable_capping_flooring 选填,默认False,True时按阈值平滑化极端值
# capping_flooring_limit 选填,默认[0.01, 0.99],平滑化处理对于分位数外的值为真实反映数据原貌,数据预处理非常简单,只有上述几个参数,其中replace_option用来做数据替换,而auto_convert_dtype是指基于train_data和test_data每一列数据的dtype都是完全一致的假设,如果发现不一致且启用参数则会进行类型转化,大概原理是数值变量按np.float_标准化,非数值变量按np.object_标准化
极端值处理一般用的非常少,因为如果flow_data_type参数是"WOE_"的话,分箱本身就具备极端值处理的功能,enable_capping_flooring和capping_flooring_limit一般常用在flow_data_type为"ORI_"(或save_ori)且后续建模类型为基于capping和flooring处理后的数据集建模的情况下才使用,最常见的场景可能是基于极端值处理后的线性回归建模,整体使用频率不高
2.3 标签定义
二分类任务最重要的一步就是定义目标变量,在分析时采用1和0来表示,一般来说,会使用1代表有表现的数据(逾期客户、响应客户、目标客户等),使用0代表无表现的数据(正常客户、沉默客户等)
# 基础定义
# ind 选填,默认2,响应中的不确定值
# bad 选填,默认1,响应中的negative
# good 选填,默认0,响应中的positive
# response 选填,默认为"target",数据的标签列不过如果大家项目做的多就会发现很多时候是需要有一个中间状态的体现的,比如:
- 逾期分析时按逾期天数计算滚动率发现,>=30天的逾期天数为目标客户(标记1)
- 和<=3天的逾期天数为正常客户(标记0)
- 那么(3, 30)之间的客户应该怎么处理呢?(标记?)
有些朋友说,我分析的时候把这些数据删了,不考虑不就行了?
直接删除数据其实是不建议的,因为如果你删除了这些特殊状态的客户,可能01分析的时候没有太大影响,但是是会影响到全量综合测算的(因为会影响分母大小),比如按01分析一条规则的测算命中率是3%,把2加进去的时候可能实际命中率就只有2.5%了,还没有正式投产测算就发生偏移是非常不专业的做法
还有些朋友说,我就不设置中间状态只保留01,把中间状态设成0或1,不就没这个问题了?
这种情况也是不建议的,01的定义是会直接影响到后续有效性和稳定性的,不恰当的01设置可能会导致分析的目标紊乱出现分析偏差(如:分箱切分点阈值偏移),况且谁也不能保证永远没有特殊状态的存在(比如我把未激活的客户当作2来评估分布)
所以我设计的模块虽然针对二分类,但标签定义默认是能包含012三种状态的,2可以配合各种不同状态(未激活、沉默、被拒绝、营销未响应等)中间状态的数据集进行测算和展示,如下:
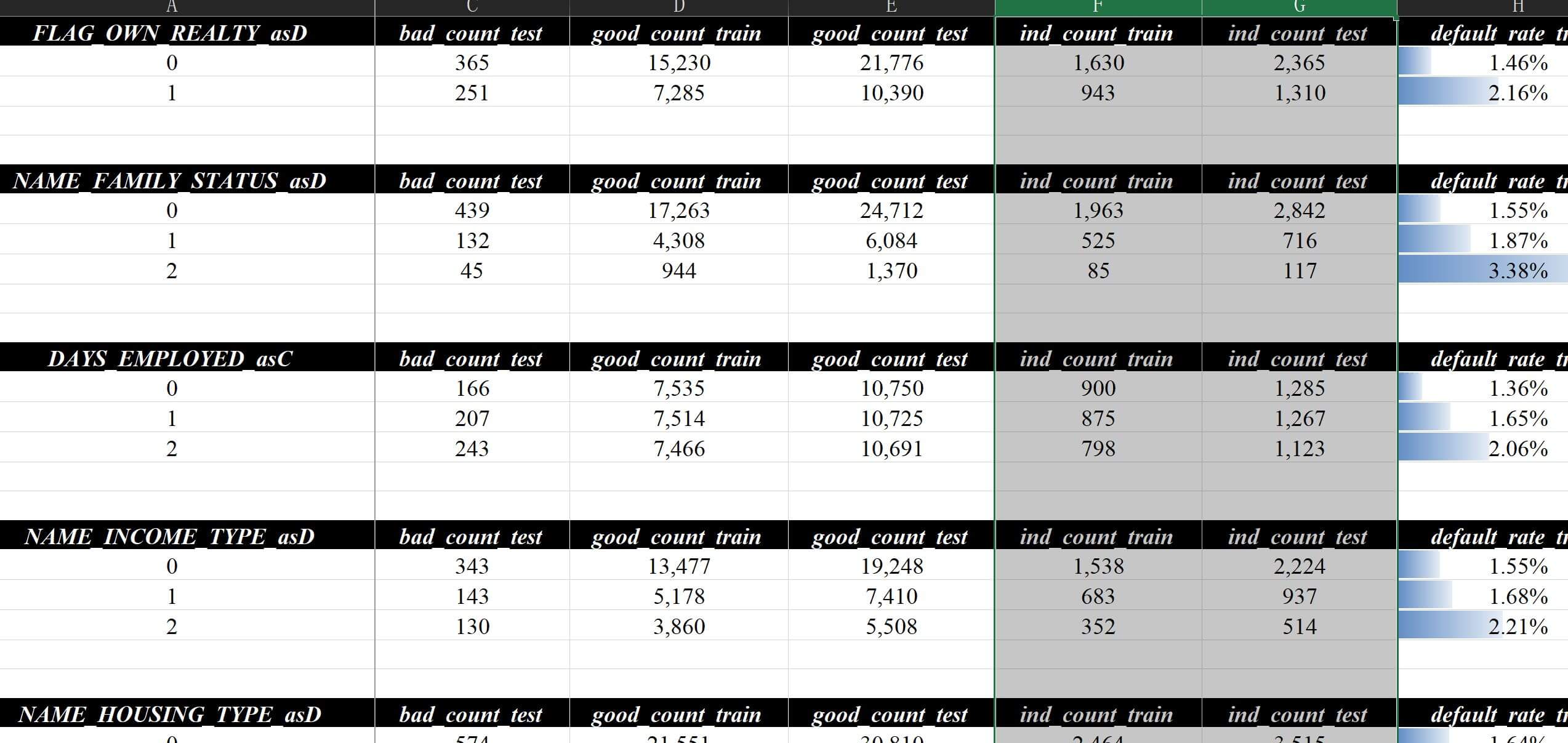
中间状态仅做展示并不影响使用01的进行核心测算和分析
这个模板其实也可以改的,主要通过修改全局模板,简单配置如下:
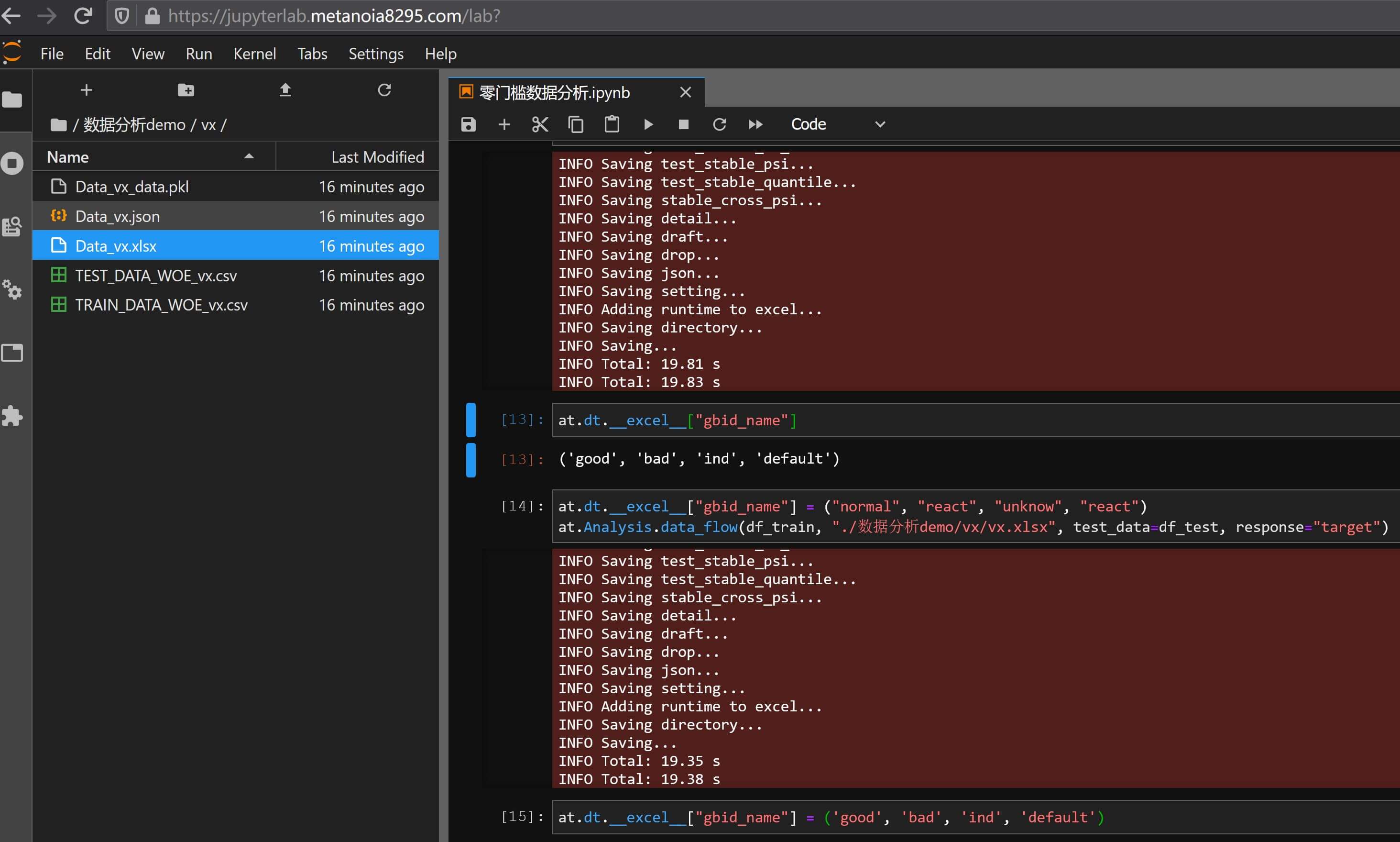
这样所有对应的bad/good/ind等名称都会发生改变,如下图所示:
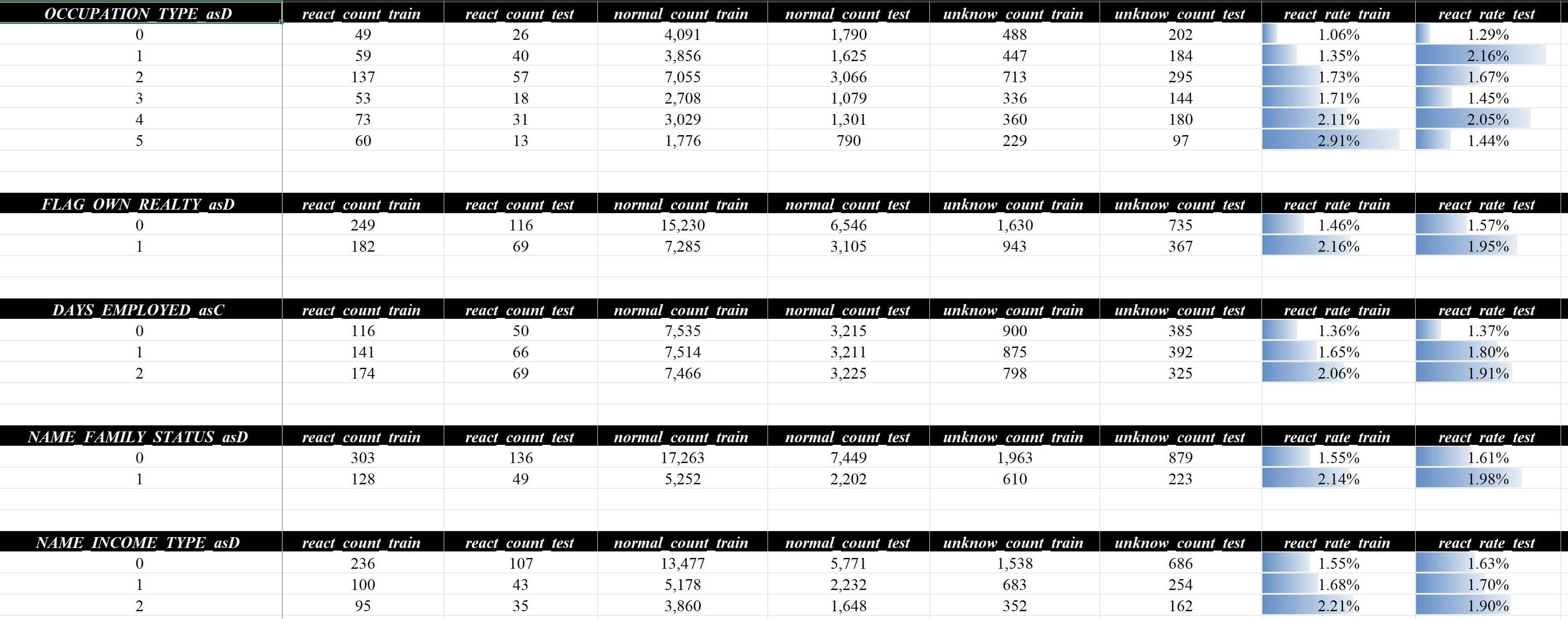
具体可以下载文件查看:数据分析报告vx.xlsx,参数调整范围也可查看6.1 报告格式调整
2.4 数据切片
数据切片是可选的参数,但因为实在是太基础了,所以提前说一下,细心的朋友可能会发现上面展示的报告内容里面有好多Random1/2/3是怎么回事?比如这一页:
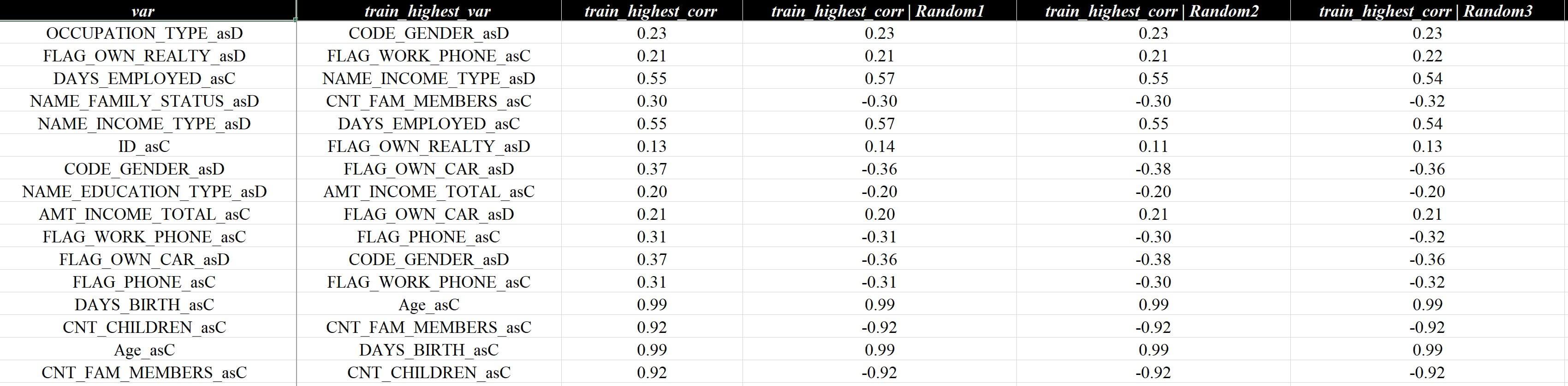
上面报告当中的Random1/2/3其实是代码生成的数据切片的一种,上图的具体含义是在计算相关性时,除了按整体数据量计算,还把数据集分为Random1/2/3三片,每片数据分别计算相关性,最后汇总展示,
那么来看一下数据切片设定的参数定义:
# 数据切片相关
# split_col_name 选填,默认None,可选时间序列或离散值,用来对数据进行分割
# is_time_series 选填,默认True,当输入非响应列时,按时间序列预先分割处理
# use_train_time 选填,默认False,处理时间时,使用开发时间区间来映射全局
# max_split_part 选填,默认10,支持的数据切片的上限,过大会导致性能问题
# format_time_edge 选填,默认False,当处理时间时,时间区间两端展示为无穷
# stratified_split 选填,默认False,等量分割数据抽样时,是否使用分层抽样
# split_data_method 选填,默认3,可选"M"/"2W-SUN",int时使用等量分割
# split_random_state 选填,默认None,数据在按时间划分抽样时的随机种子
# use_response_split 选填,默认True,当split未指定时采用response默认当split_col_name留空且use_response_split时,会根据response随机三等分数据集,当然可以按任意字段来进行切片分群,一般时间字段用的比较多,比如我希望把数据集按出生时间(年龄)进行切片来查看对比不同年龄段的客群是否在数据表现上有差异,则输入:
# 首先生成出生年份字段并分群(直接基于train/test赋值会有个warning不推荐)
from sklearn.model_selection import train_test_split
df_['birth_year'] = df_["Age"].map(lambda x: str(2021 - x) + "0101")
df_data = df_[df_["target"].notnull()]
df_train, df_test = train_test_split(
df_data, test_size=0.3, stratify=df_data["target"], random_state=42)
# 指定字段做为切片,不修改其他参数,默认is_time_series按时间序列处理
at.Analysis.data_flow(
df_train, "./数据分析demo/v2/v2.xlsx", test_data=df_test, response="target",
split_col_name="birth_year",
)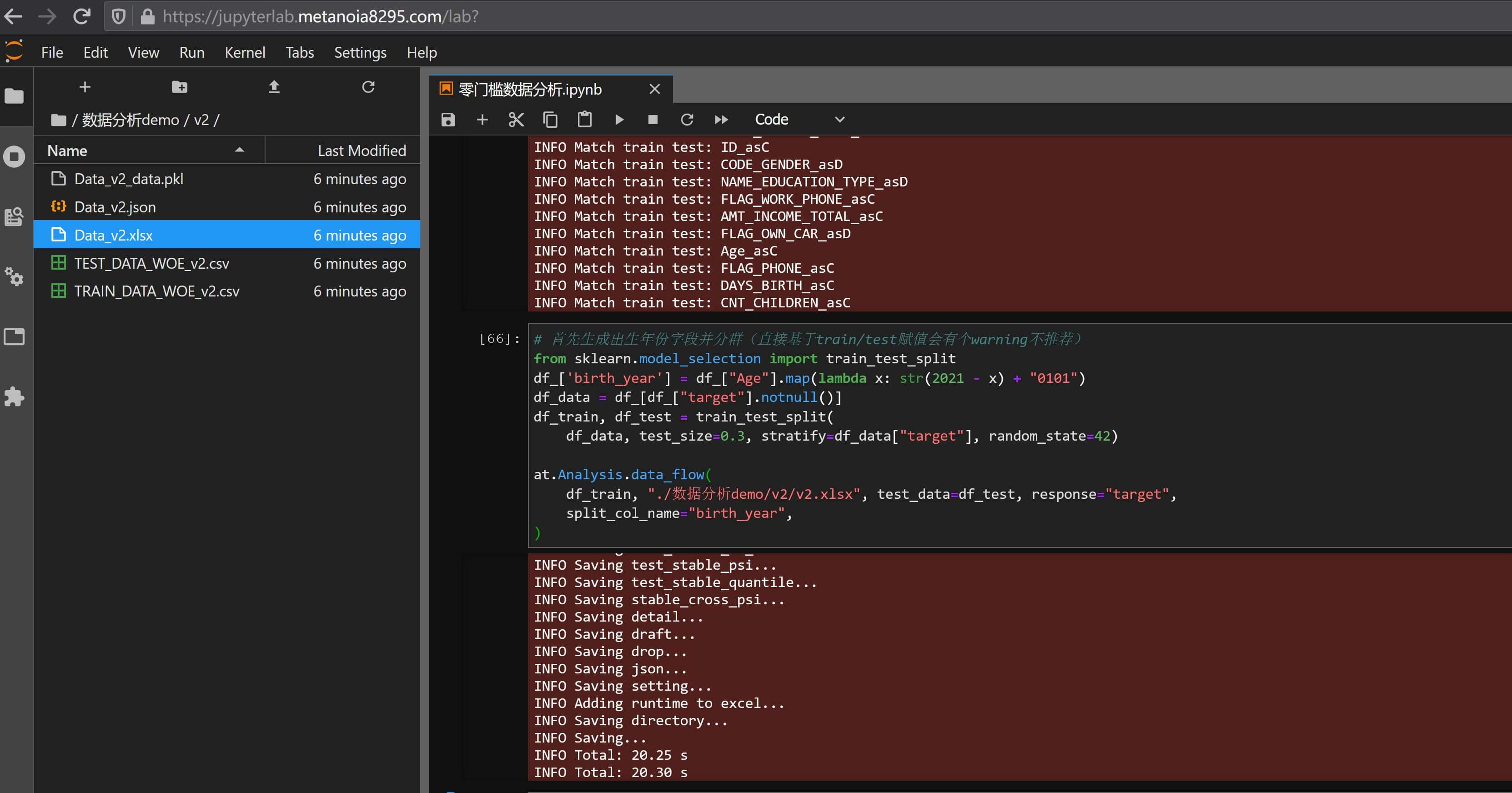
目前切片调整为按出生年份分群三等分并应用到所有分析结果中,具体可以下载文件查看:数据分析报告v2.xlsx
其中随便看一页变量评估 - 分布稳定性 - 开发,虽然默认离散值是应用自动合并分箱算法的,但也能明显看到年龄较高的人群中职业这个指标为缺失的数据占比异常的高,如下:
train)
并且这个现象在train/test中是非常稳定的,在变量评估 - 分布稳定性 - 验证也可以看到非常相似的现象:
test)
以上是简单的数据切片举例,这里只花了几秒扫了一眼就发现了一个数据集上的特点,当然只针对这个点我也可以直接写代码来验证并得到一样的结论: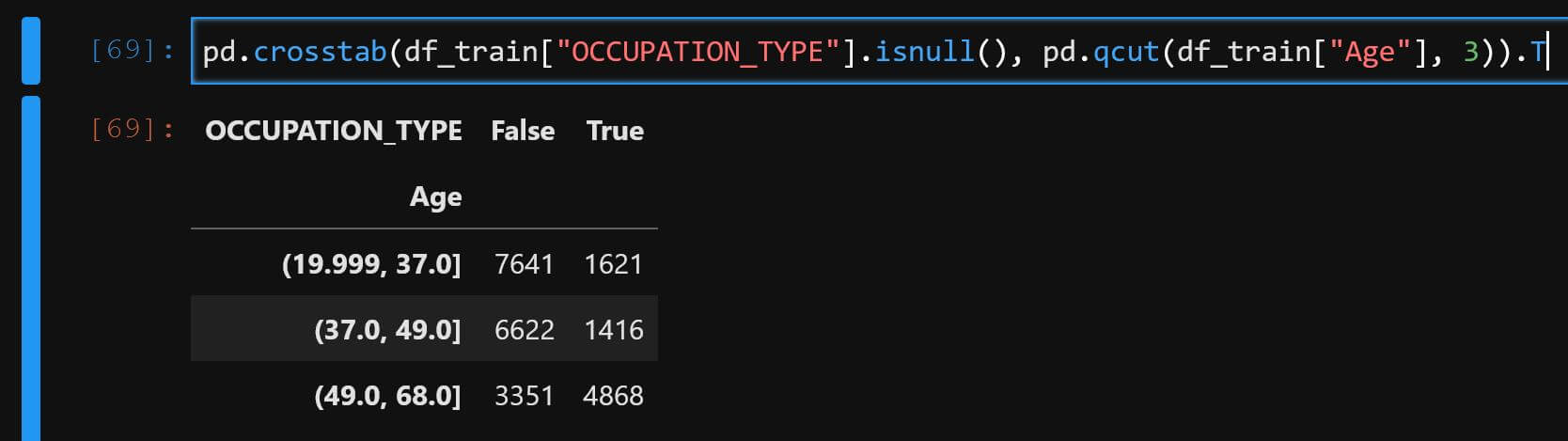
这个点的分析我在Kaggle上没见到多少,基本都是直接掉包刷结果,这也是竞赛和业界在实战上关注点差异化的体现之一,毕竟竞赛也没法针对数据集进行底层颗粒度的成因分析来反向优化数据,
但在业界直接掉包刷结果是远远不够的,如果在分析的时候底层数据基础都存在争议,后面无论是建模挖掘还是策略分析都很容易因为得不到认可而反复推倒重来,这里是样例数据就不过多展开分析上的描述了
2.5 多数据映射
上述test_data的定义为None或dataframe,实战中会面临多个数据集的测算需求,如:验证、测试、样本外、全量等不同维度,考虑到这些需求,实际上test_data是支持list入参的,参数如下:
# alpha_tools.Analysis参数
# train_name 选填,默认None,train_data的名称,入参str并和test_names联动
# test_names 选填,默认None,test_data(s)的名称,入参str/list并和test_data(s)联动
# auto_dir_cn 选填,默认True,根据train_name和test_names自动修改train_test_dir_cn值只是test_data为list时,需要同时指定train_name和test_names,不然会报错,参考用例如下:
at.Analysis.data_flow(
df_train, "./数据分析demo/v2-more/v2-more.xlsx",
# 同时入参两个数据集:测试、全量
test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"],
response="target", split_col_name="birth_year", use_train_time=True,
)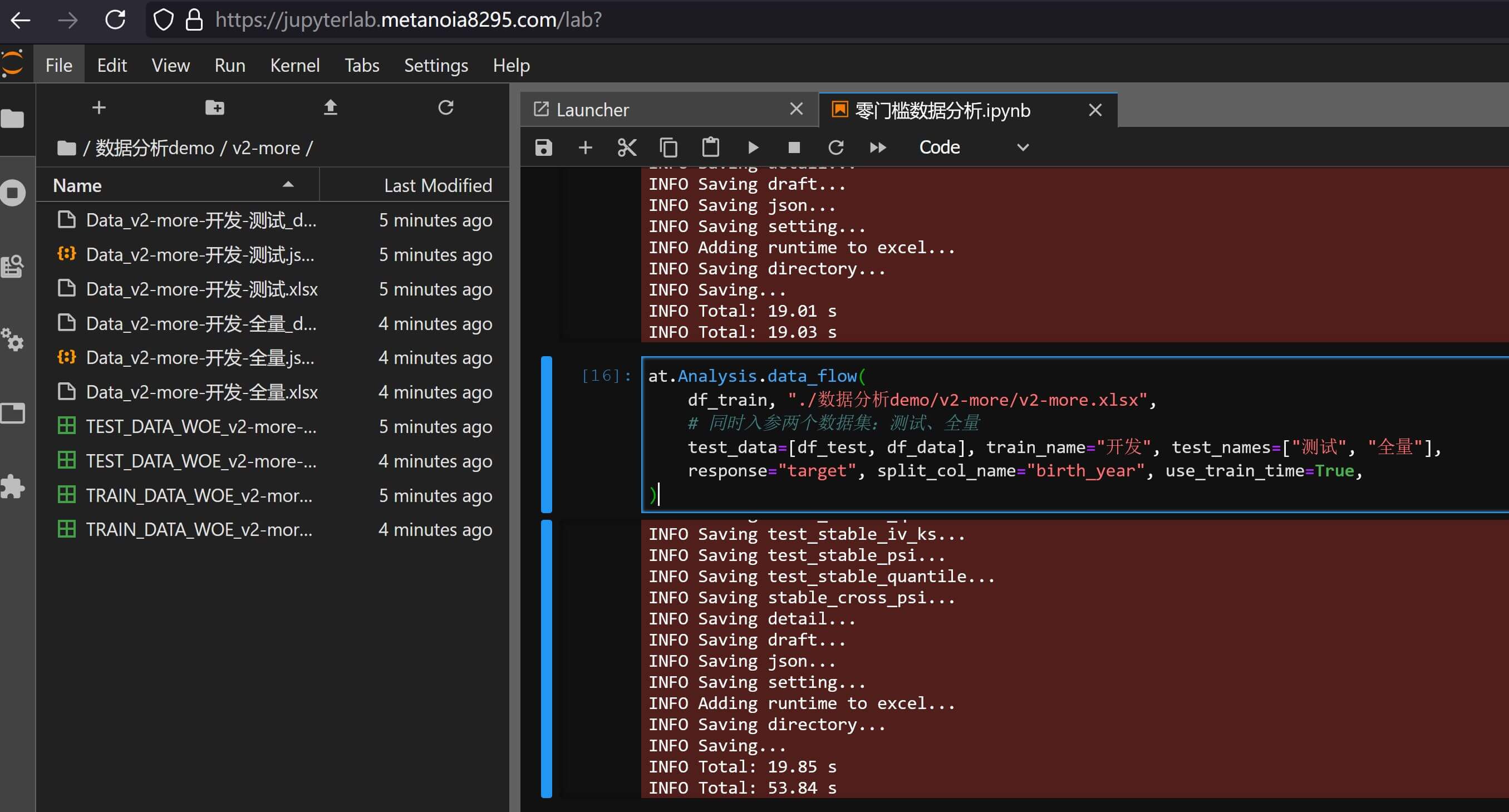
可一次性得到多个数据集的分析结果报告,并会基于output_name自动添加后缀名,如上图展示的数据分析报告v2-more-开发-测试.xlsx和数据分析报告v2-more-开发-测试2.xlsx,
具体实现上其实是通过配置文件还原的方式来操作,后面章节6.3 配置映射和还原会展开描述,至于多份文件如何合并与浏览?也会在后面章节6.5 报告合并与数据合并中具体展开描述
2.6 权重调整
权重方面是完整做好功能点接入的,通过入参sample_weight_name即可实现,比如假设我需要把response=1的样本的权重调整为原来的2倍,则输入:
from sklearn.model_selection import train_test_split
# 添加时间
df_['birth_year'] = df_["Age"].map(lambda x: str(2021 - x) + "0101")
# 添加权重
df_["weight"] = df_["target"].map(lambda x: 2 if x == 1 else 1)
df_data = df_[df_["target"].notnull()]
df_train, df_test = train_test_split(
df_data, test_size=0.3, stratify=df_data["target"], random_state=42)
# 计算
at.Analysis.data_flow(
df_train, "./数据分析demo/v2-weight/v2-weight.xlsx", test_data=df_test, response="target",
split_col_name="birth_year", sample_weight_name="weight",
)直接来看调整以后的结果文件数据分析报告v2-weight.xlsx,简单看一下数据描述和细分详情: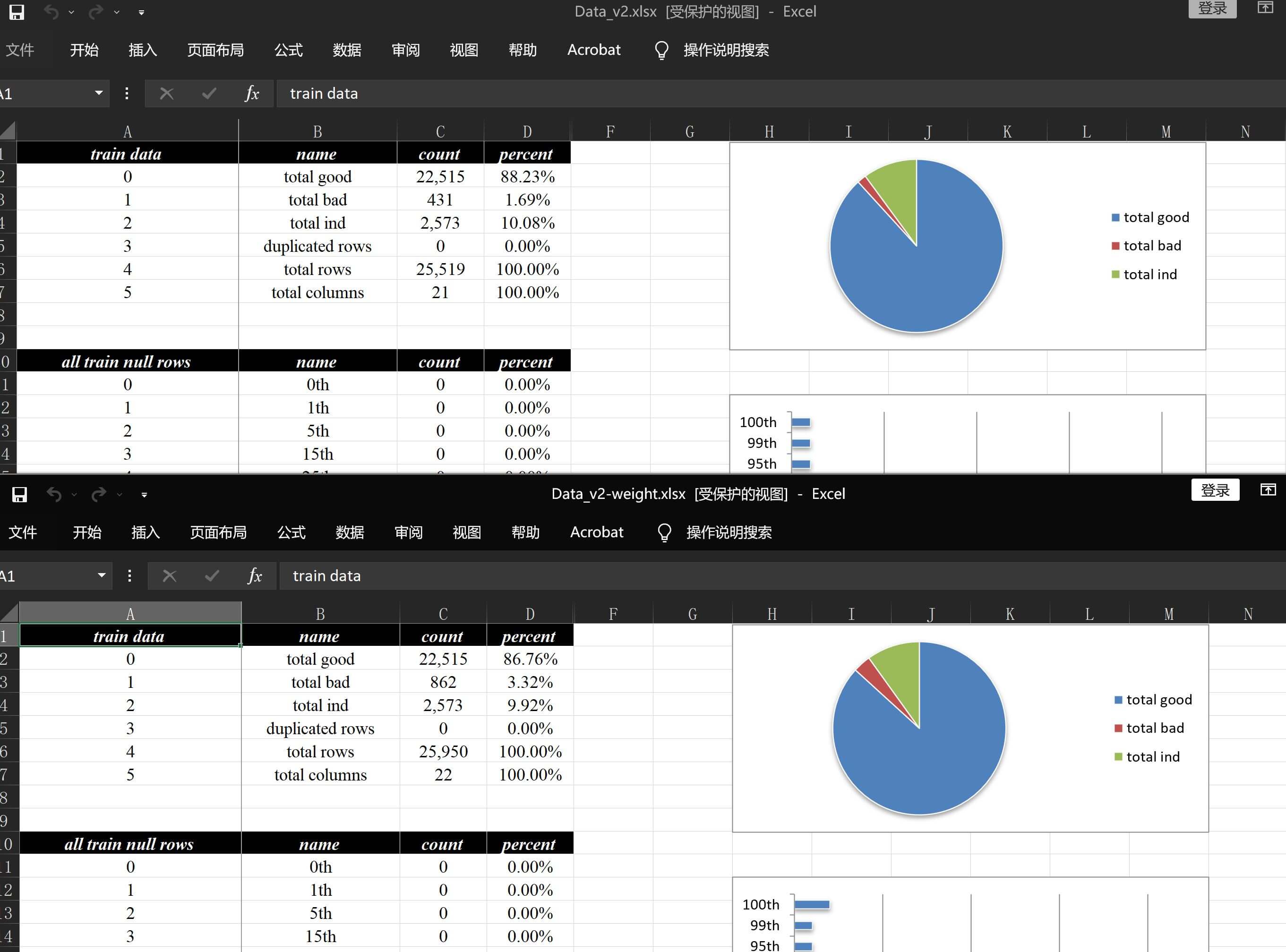
数据描述)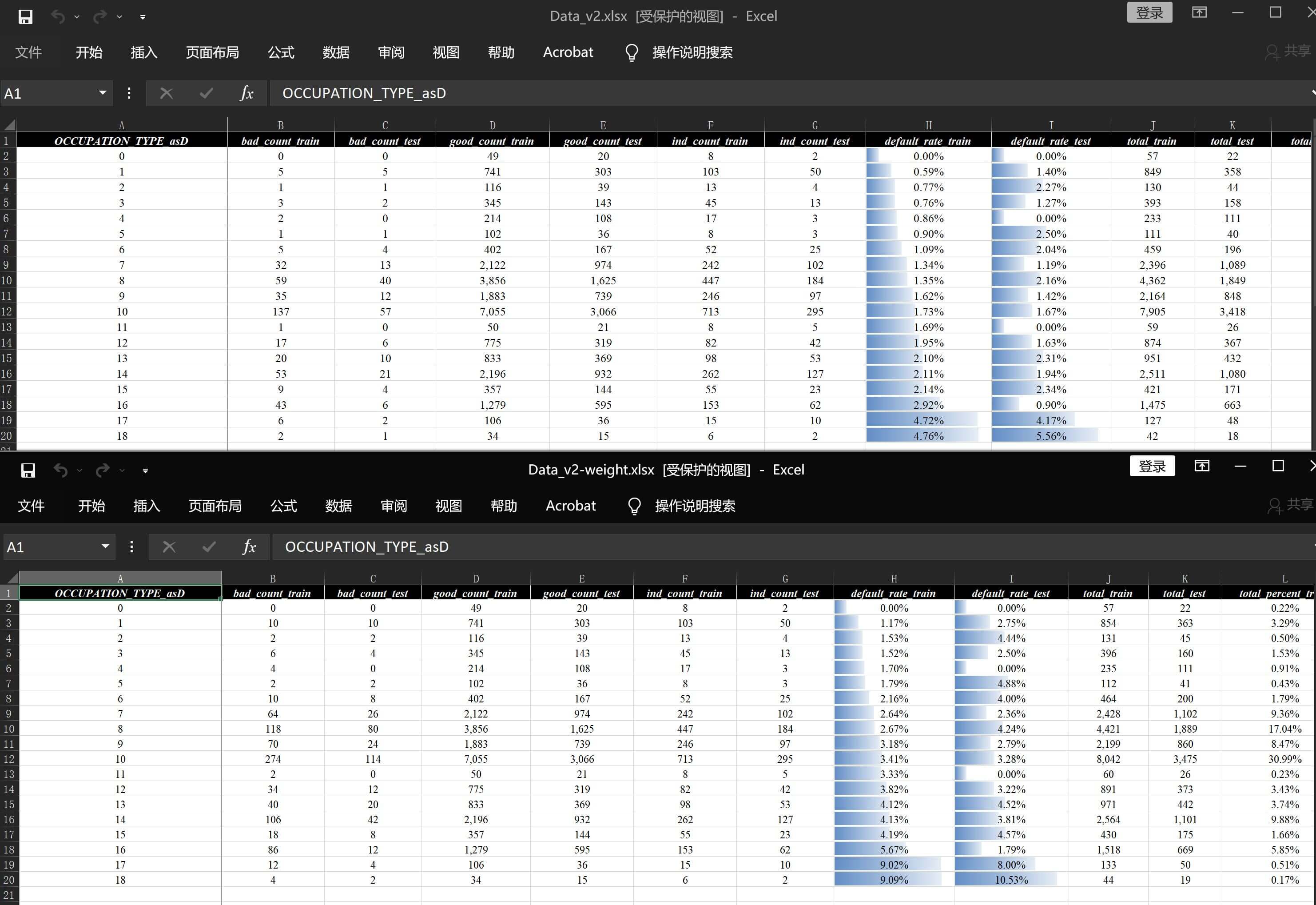
细分详情)
bad刚好是原来的2倍,当然这里也是支持小数的,比如输入:
from sklearn.model_selection import train_test_split
# 添加时间
df_['birth_year'] = df_["Age"].map(lambda x: str(2021 - x) + "0101")
# 添加权重,调整为1.5
df_["weight"] = df_["target"].map(lambda x: 1.5 if x == 1 else 1)
df_data = df_[df_["target"].notnull()]
df_train, df_test = train_test_split(
df_data, test_size=0.3, stratify=df_data["target"], random_state=42)
# 计算
at.Analysis.data_flow(
df_train, "./数据分析demo/v2-weight2/v2-weight2.xlsx", test_data=df_test, response="target",
split_col_name="birth_year", sample_weight_name="weight",
)再来看数据分析报告v2-weight2.xlsx原来两张表,则会变成1.5倍: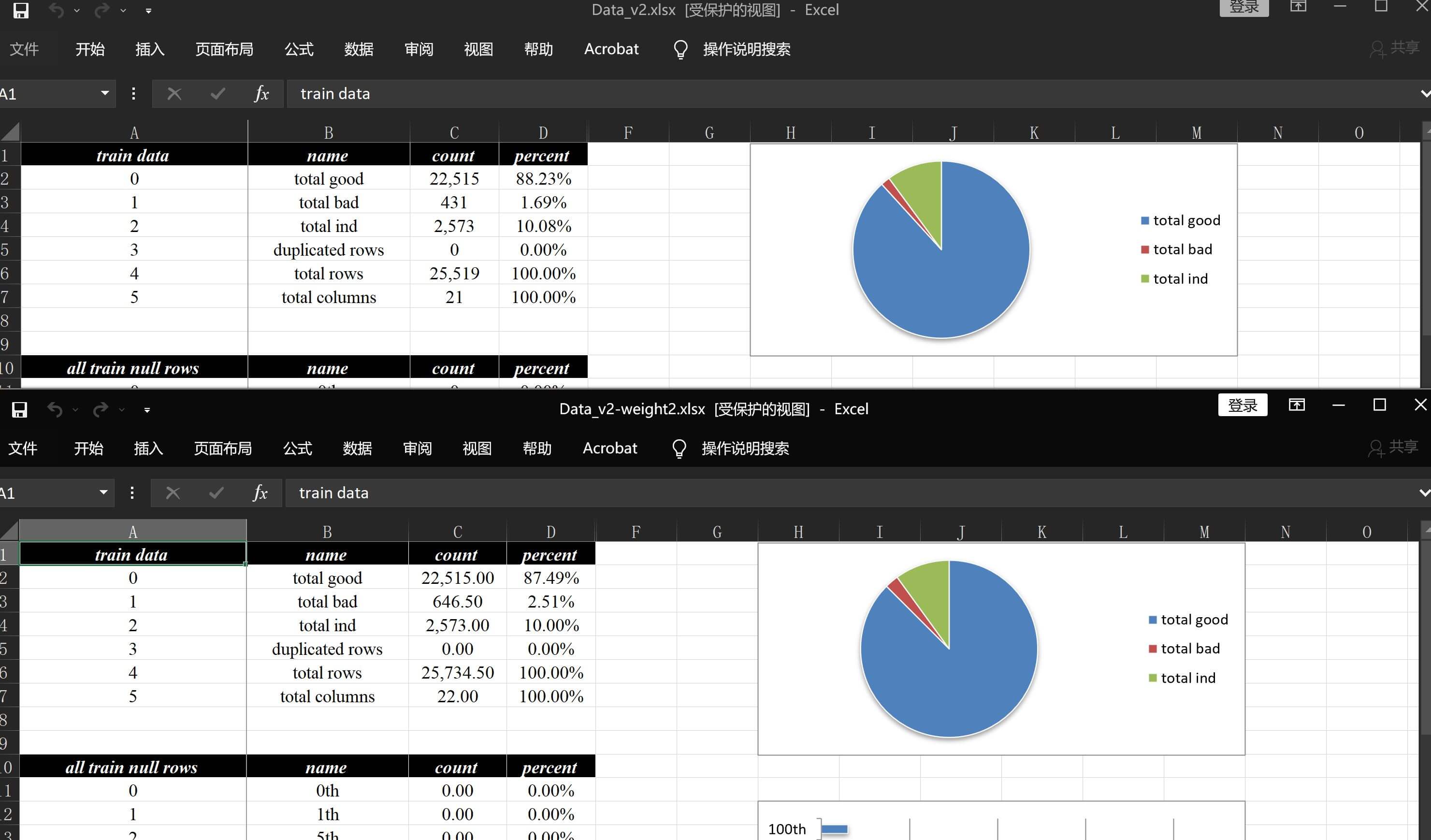
数据描述)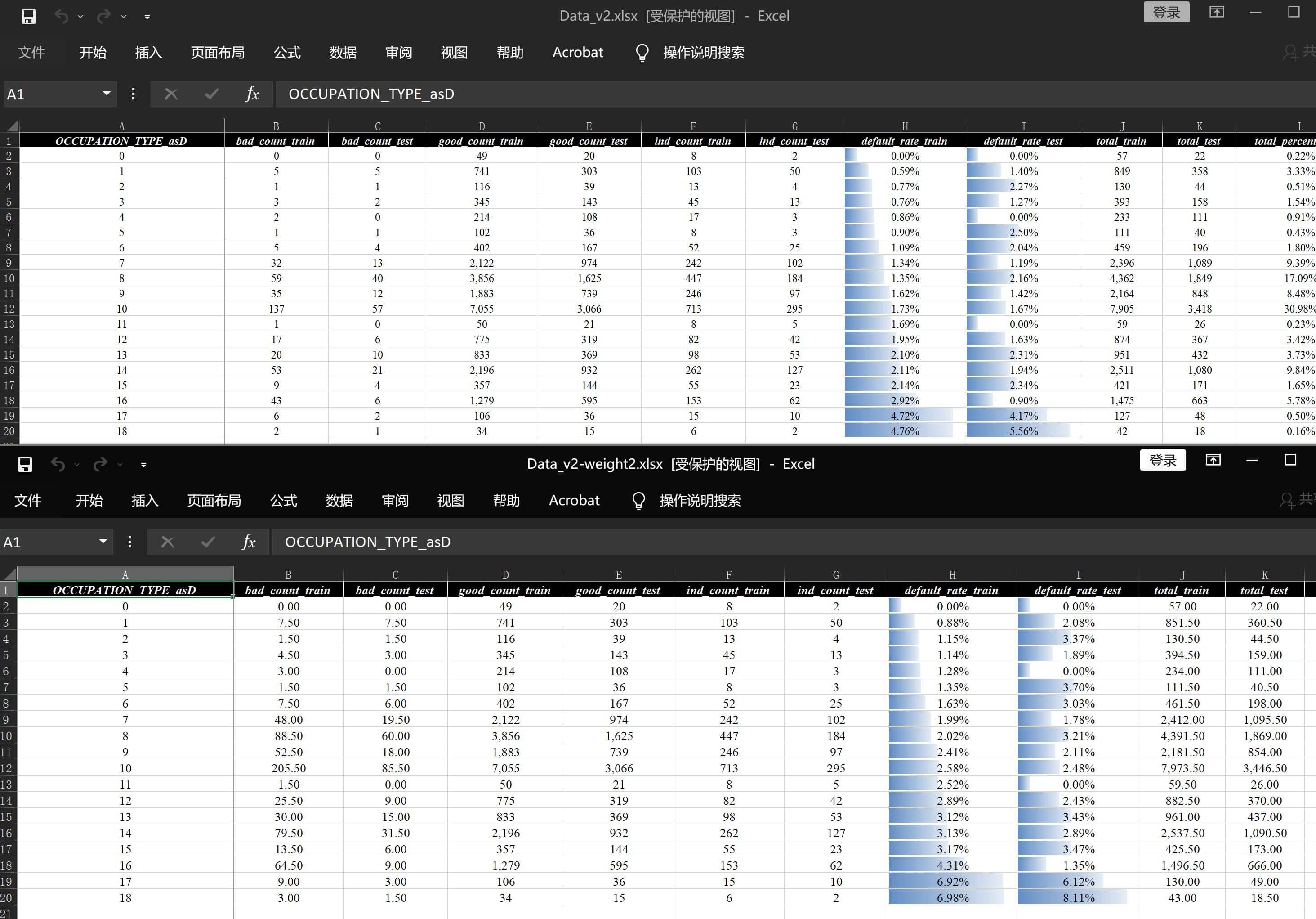
细分详情)
所有数据展示的地方全部都会对应调整和展示,这个功能点实战用的不是特别多,一大因素是原始数据样本的缩放操作存在较大争议,有可能缩放以后测算效果比不缩放好很多,但是效果衰减很快,就比较难定位原因了,
不过有些场景可能有奇效,这里篇幅有限,以后有机会再写
2.7 数据项翻译
一般来说直接使用原始数据分析即可,也可以直接修改原始dataframe.columns来调整报告内容,不过总有一些情况要求既保留原始数据内容,又体现内容转换,因此做了这个翻译方面的定义,具体内容如下:
# 数据翻译
# var_dict_path 选填,默认None,变量翻译的字典路径
# var_series_name 选填,默认"var_name",变量文件字典中待翻译变量的列名称
# var_explain_name 选填,默认"var_explain",变量文件字典中变量解释的列名称举例来说,假如我自定义了一份字段翻译.xlsx并放在同一路径下,里面包含的内容如下: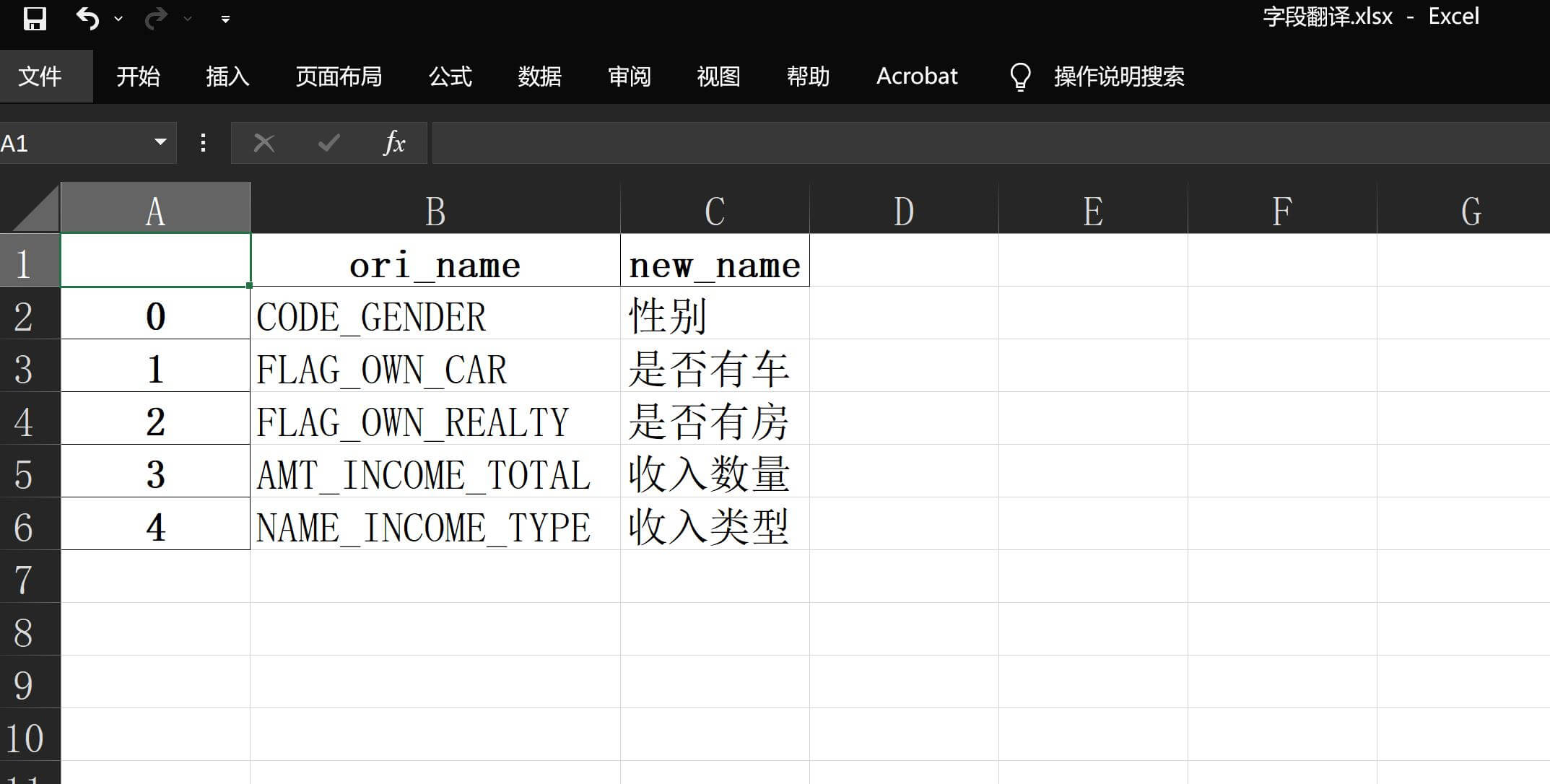
在使用的时候直接指定参数即可:
at.Analysis.data_flow(
df_train, "./数据分析demo/v2-rename/v2-rename.xlsx", test_data=df_test, response="target",
split_col_name="birth_year",
var_dict_path="./字段翻译.xlsx", var_series_name="ori_name", var_explain_name="new_name"
)可在输出结果数据分析报告v2-rename.xlsx相应的位置看到已经完成了翻译标注: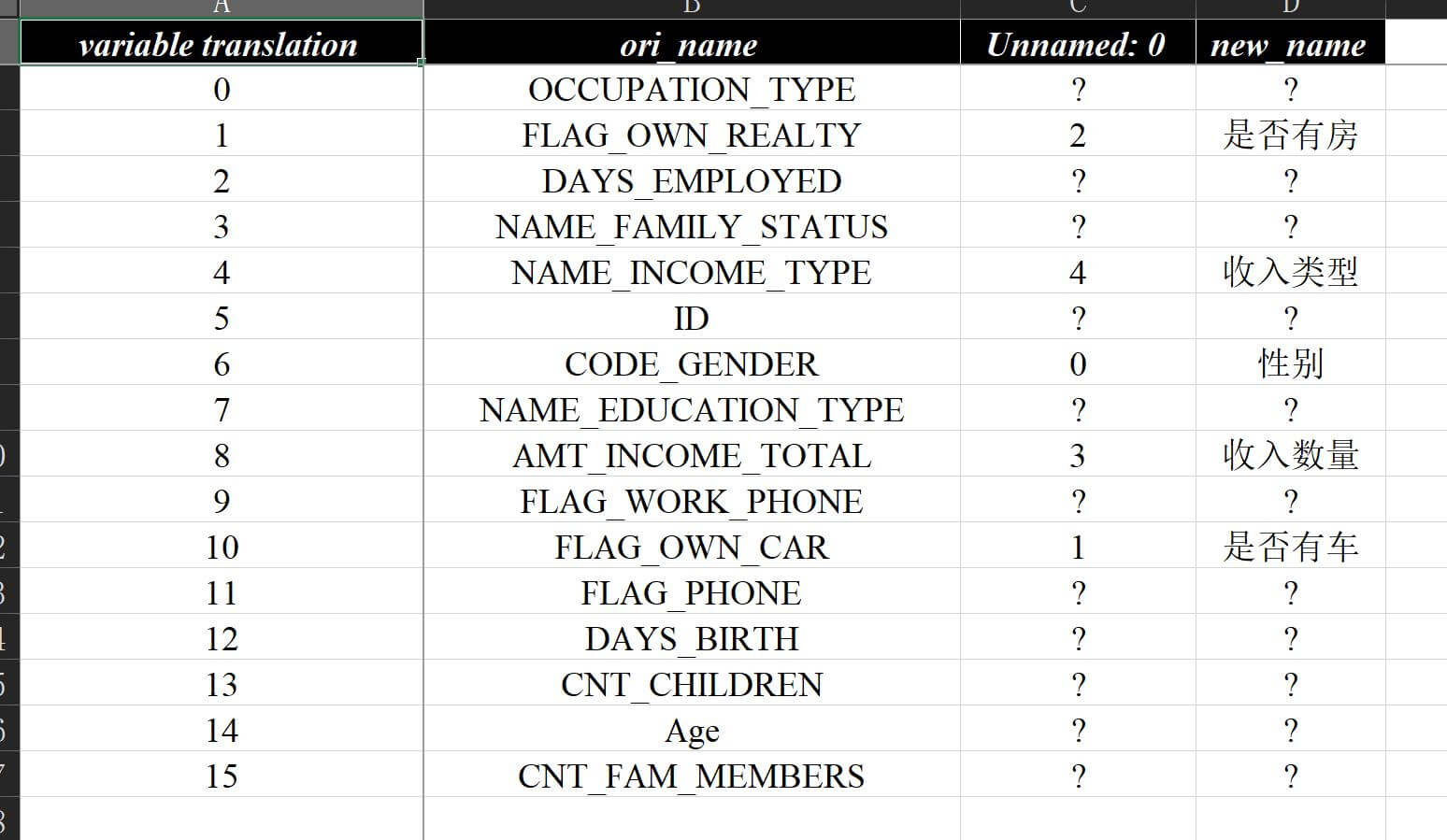
其中变量评估 - 翻译页会把字段翻译.xlsx中匹配到的行的所有列全部粘贴保留
2.8 高性能实现
除了底层混用python/c/c++实现高性能计算函数,在变量分析的流程是默认开启并发的,能同时平行加速处理多个变量缩短整体分析时间,涉及的参数如下:
# 并发相关
# multi_num 选填,默认8,多进程或多线程的并发数
# chunk_size 选填,默认1,多进程时每个进程包含的并发数
# enable_lock 选填,默认True,并发锁,可间接调整并发运行状况
# enable_multi 选填,默认True,是否启用多进程或多线程加速计算参数比较简单不再展开描述,其他实践中的一些简单备注事项如下:
3 数据预览
3.1 统计分布与缺失分布
整体评估 - 数据描述这一页面会带有基础统计信息和缺失分布(行缺失、列缺失)情况,参考如下:
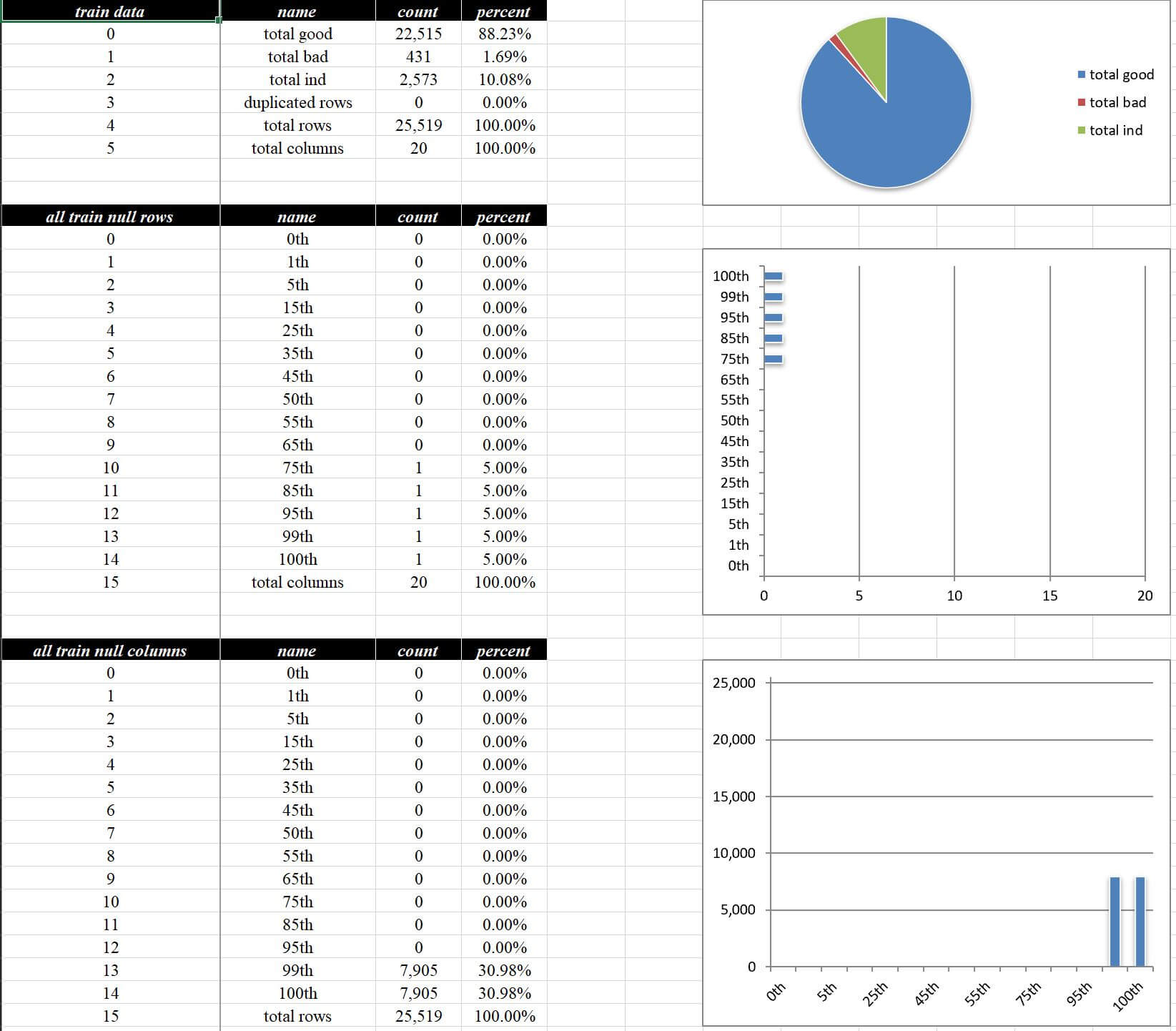
这个数据集因为缺失不多,所以缺失分布表现的不明显,和这一页相关的主要有这几个参数:
# 输出相关
# save_desc_info 选填,默认True,是否输出数据集的描述性统计相关的信息
# split_desc_info 选填,默认False,True时添加desc_info的切片输出的信息
# 数据存储相关
# save_null_count 选填,默认False,是否将缺失分布的原始数据存为文件此处需要注意save_desc_info会统计duplicated rows重复行的情况,如果表太大的话此处可能会是性能瓶颈,需要描述信息切片展开的话使用split_desc_info输入:
at.Analysis.data_flow(
df_train, "./数据分析demo/v3/v3.xlsx", test_data=df_test, response="target",
split_col_name="birth_year", split_desc_info=True
)可以查看这个文件数据分析报告v3.xlsx,也可以看下面的视频,
一般来说,这个输出会感觉内容多到有点冗余,所以默认不开启split_desc_info
3.2 交叉透视表
整体评估 - 交叉分布这里可以查看到基础的交叉分布,整体如下:
默认是输出切片与response之间的分布,也可以查看任意数据与response之间的分布,主要参数有:
# 交叉透视表相关
# cross_response 选填,默认None,支持str和list,交叉分析标签
# cross_split_detail 选填,默认False,添加split_col_name原始值的交叉表
# cross_split_summary 选填,默认True,添加split_col_name加工切片的交叉表例如我想知道NAME_FAMILY_STATUS与NAME_INCOME_TYPE和response之间的交叉矩阵,则输入:
at.Analysis.data_flow(
df_train, "./数据分析demo/vz/vz.xlsx", test_data=df_test, response="target",
split_col_name="birth_year",
cross_response=["NAME_FAMILY_STATUS", "NAME_INCOME_TYPE"],
)默认会包含切片的分布,可以在文件数据分析报告vz.xlsx这一页看到这样的结果:
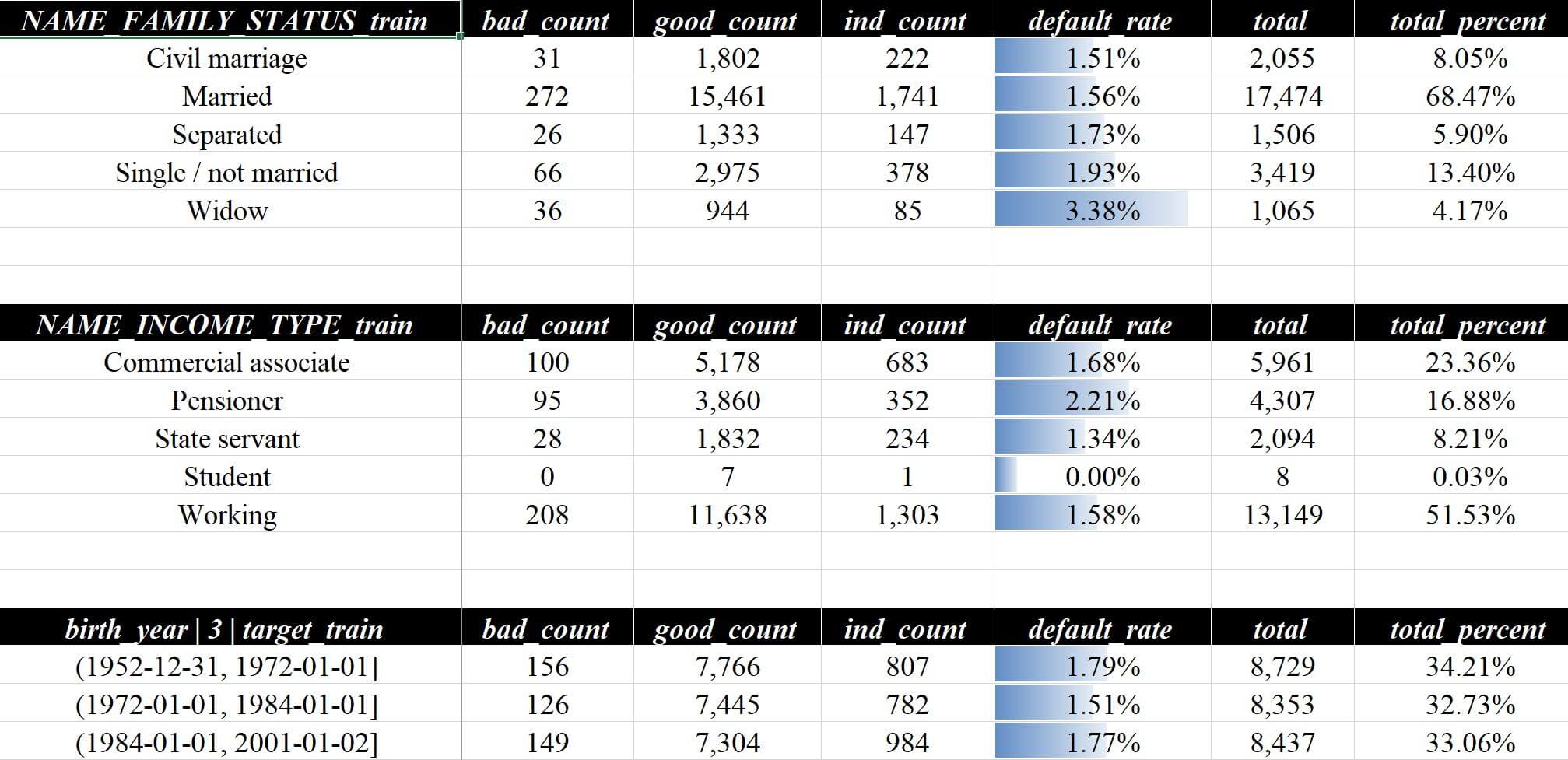
当时设计这个功能本意是做数据分群等方面的数据预览,但是后面发现因为分箱展示时会有变量评估 - 细分详情,功能覆盖上稍微会有点重复,不过交叉透视表不会被exclude_column排除,所以还是有一些独特的使用场景
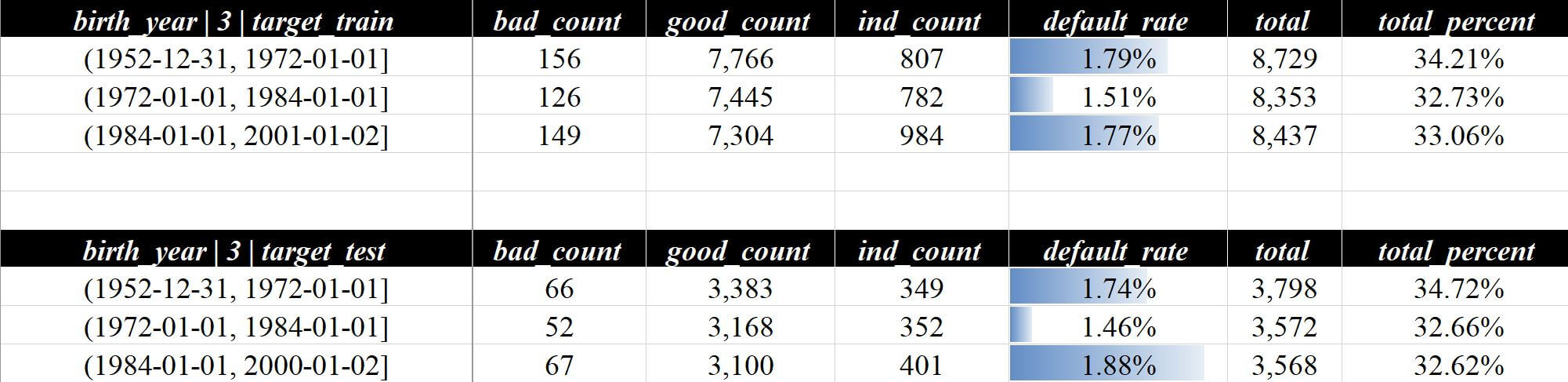
3.3 数据唯一性
整体评估 - 数据唯一性这一页会包含一些数据唯一性的分析,例如我在设定birth_year做为切片后,会自动统计birth_year的唯一个数,输出结果如下:
birth_year)
结果好像不太对?主要是因为train/test的切片都是分别在各自的数据集中等量切片导致最大值不同,train/test切片对不起来的地方会自动0值填充,那先来调整一下,因为这个数据集train/test的分布比较接近,因此可以直接使用train切片的计算的区间来映射处理test数据集:
at.Analysis.data_flow(
df_train, "./数据分析demo/v4/v4.xlsx", test_data=df_test, response="target",
split_col_name="birth_year", use_train_time=True,
)现在再来看数据分析报告v4.xlsx里面整体评估 - 数据唯一性这一页的结果就非常合理了:
birth_year)
这一页涉及的参数一共只有两个:
# 输出相关
# add_info 选填,默认None,添加的列,支持str和list
# add_unique_info 选填,默认True,True时对add_info项进行数据唯一性分析add_info一般用来输入主键和关联信息,避免输出的数据无法关联,假设现在需要统计ID的唯一值,可以用来确保数据主键的唯一性,避免分析完了发现有几条数据虽然不重复在duplicated rows中无法显示,但ID竟然一样的错误数据的情况的发生,输入并查看结果:
at.Analysis.data_flow(
df_train, "./数据分析demo/v5/v5.xlsx", test_data=df_test, response="target",
split_col_name="birth_year", use_train_time=True, add_info="ID"
)
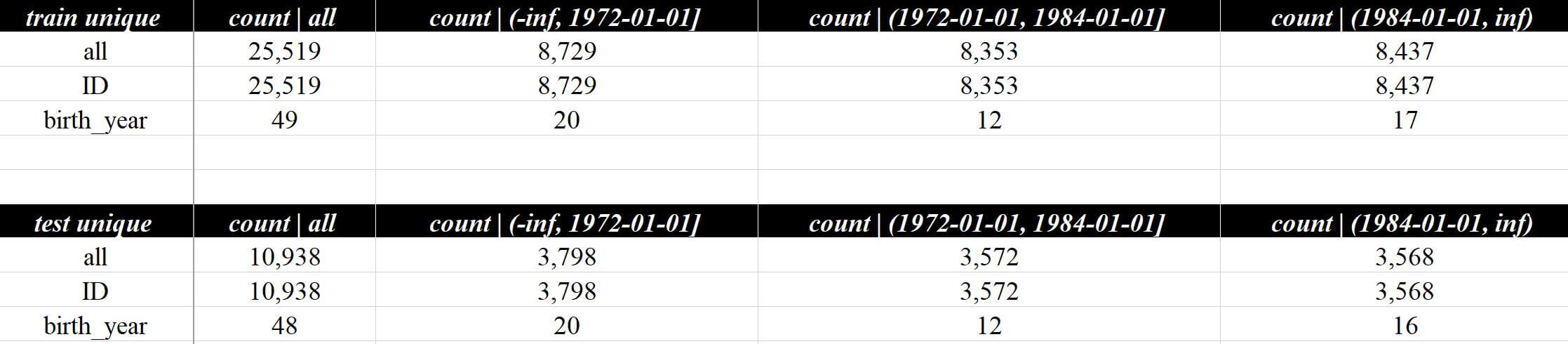
birth_year & ID)从分析来看ID的唯一性没什么问题,而且在add_info中添加的变量会自动加入exclude_column中,同时修正了在变量评估 - 分析汇总这一页中看到的ID被错误的识别为数值型变量的问题,可以查看分析报告数据分析报告v5.xlsx
3.4 分析汇总
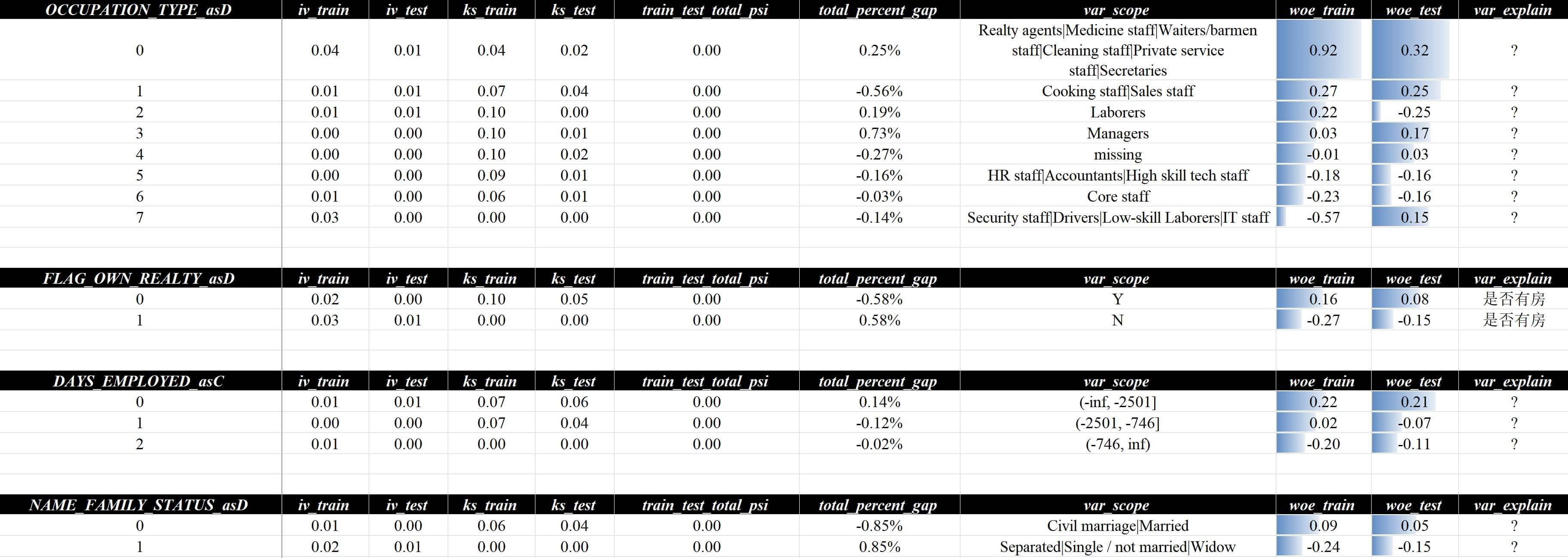
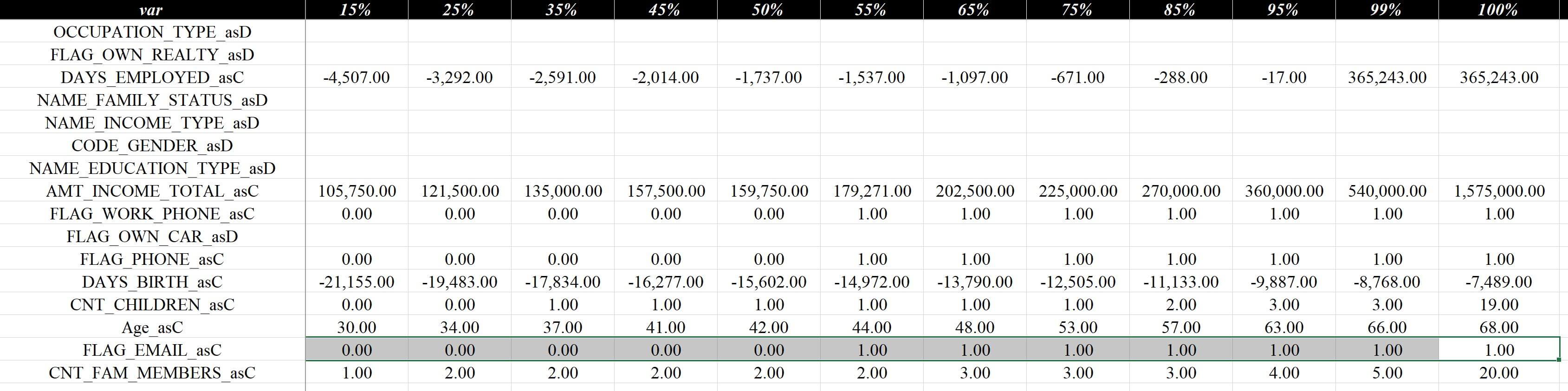
在变量评估 - 分析汇总这一页中,可以看到所有指标的单变量分析的汇总结果,每个变量分别用_asC和_asD代表连续数据(Continuous Data)和离散数据(Discrete Data)做为后缀,汇总内容包含了IV、KS、分箱单调性、缺失值、分位数、唯一个数、最大单一值占比、还有各类稳定性等,页面的部分截图如下:
这一页中,名称和对应的描述参考如下:
| 名称 | 描述 |
|---|---|
| var | 变量名称 |
| iv_train | IV值 - 开发 |
| ks_train | KS值 - 开发 |
| is_monotonic_train | 分箱单调性 - 开发 |
| …… | …… |
完整的名称及描述请联系作者获取密码查看:
上述的概要信息,分类后主要可归纳为以下几种:
| 名称类型 | 名称范围 |
|---|---|
| 基础描述 | var, group_num, unique_num, max_single_percent, missing_percent, std, mean, mode, median |
| 有效性 - 开发 | iv_train, ks_train, is_monotonic_train,monotonic_corr_train |
| 有效性 - 验证 | iv_test, ks_test, is_monotonic_test,monotonic_corr_test |
| 稳定性 - 开发 | monotonic_cnt_rate_train, iv_gap_ratio_train, ks_gap_ratio_train, mean_quantile_variation_train, mean_cross_psi_train, max_percent_gap_train |
| 稳定性 - 验证 | monotonic_cnt_rate_test, iv_gap_ratio_test, ks_gap_ratio_test, mean_quantile_variation_test, mean_cross_psi_test max_percent_gap_test |
| 稳定性 - 对比 | train_test_total_psi, max_percent_gap_total, iv_gap_train_test, ks_gap_train_test, train_test_iv_gap_ratio, train_test_ks_gap_ratio, train_test_cross_psi, max_percent_gap_cross |
变量评估 - 分析汇总这一页面包含了基础描述、有效性、稳定性、交叉对比分析等内容,整体上覆盖了相当多的分析维度
3.5 相关性分析
变量评估 - 相关性列表这一页展示了变量相关性最高的变量,使用WOE计算,避免了离散值无法直接使用部分算法计算相关性的问题,包含train\test和数据切片,参考如下:
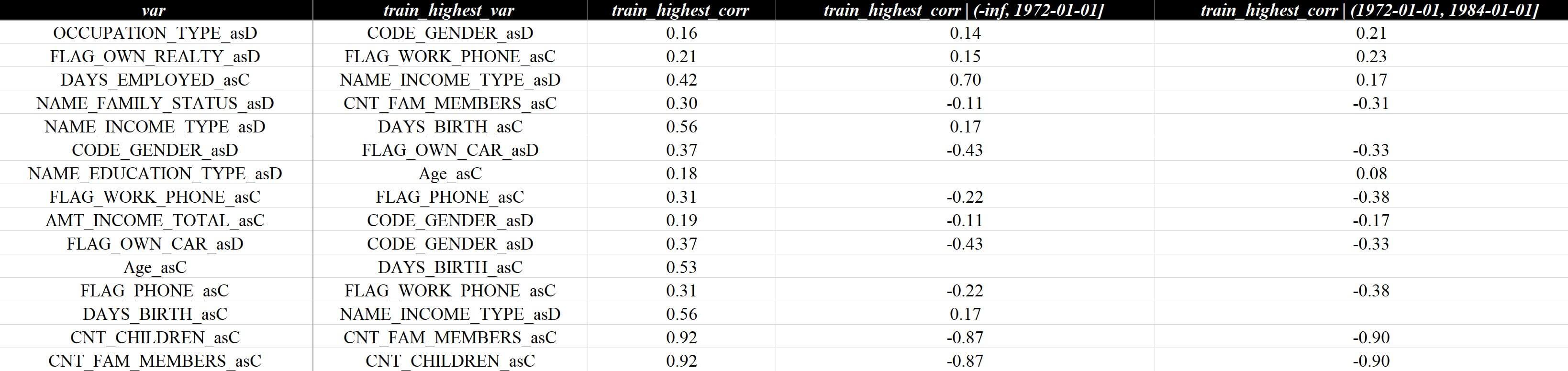
涉及的参数有:
# 输出相关
# save_corr_detail 选填,默认False,True时会输出变量维度相关性分析的明细结果
# save_corr_summary 选填,默认True,True时会输出变量维度相关性分析的汇总结果表
# corr_table_method 选填,默认"pearson",相关性的算法,可选"kendall"/"spearman"这几个参数都比较简单就不展开描述了,默认不保存相关性矩阵主要考虑到指标维度较多时二维矩阵会很大,同时相关性矩阵也是可能的分析上的性能瓶颈,如果数据量实在太大可以考虑关闭
4 数据过滤和筛选
4.1 概述
当查看变量评估 - 排除详情这一页的时候,可以在这里看到被排除的指标和排除的原因:
排除的reason中,除了手动入参str或list到exclude_column来人工排除指标以外,其他都是由参数判定来自动过滤的,具体环节包含:单一值过滤(缺失率)、离散值过滤、分箱后的有效性过滤、分箱稳定性过滤、基于切片后的波动率过滤等,本章节会逐一展开
4.2 单一值过滤
这一部分的主要参数有:
# 单一阈值筛选相关
# enable_single_threshold 选填,默认True,是否启用单变量筛选过滤变量
# single_include_none 选填,默认True,单一值计算是否包含缺失值
# single_threshold 选填,默认0.85,将保留小于该值的变量可以看到上图中single_threshold就是因为命中单一值这个条件,其中single_threshold (1)代表这个指标全都是由同一个值组成的,即使不启用enable_single_threshold也会排除,另外默认single_include_none的逻辑是把缺失值做为单一值的一种,也是业界非常常用的做法,看一下"FLAG_MOBIL"的分布验证一下: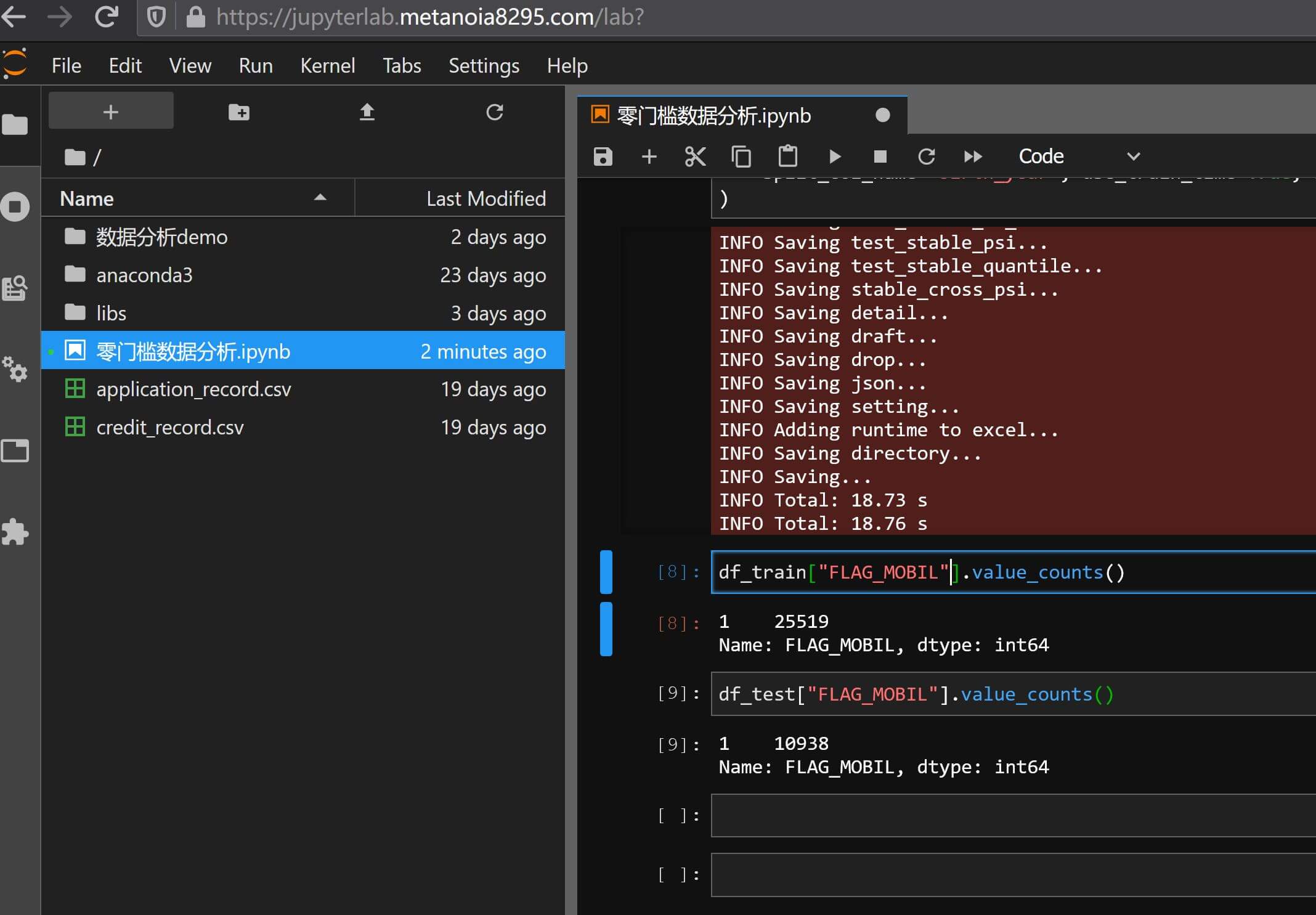
考虑到这个数据集指标维度范围较小,下面来做调整,关闭enable_single_threshold,
at.Analysis.data_flow(
df_train, "./数据分析demo/v6/v6.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
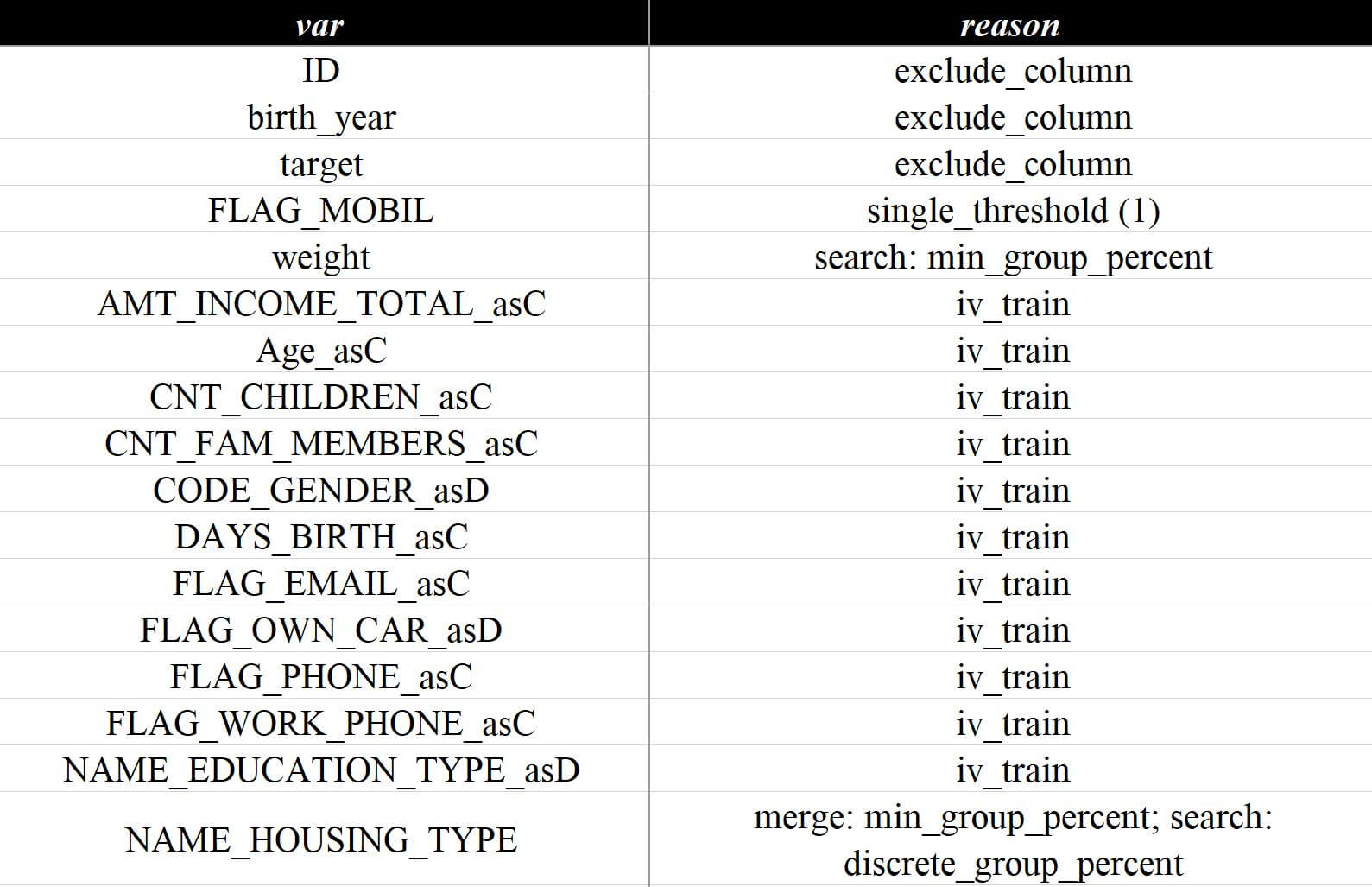
)来看数据分析报告v6.xlsx这个文件的变量评估 - 排除详情页面,前面因为单一值过滤的数据已经纳入分析范围: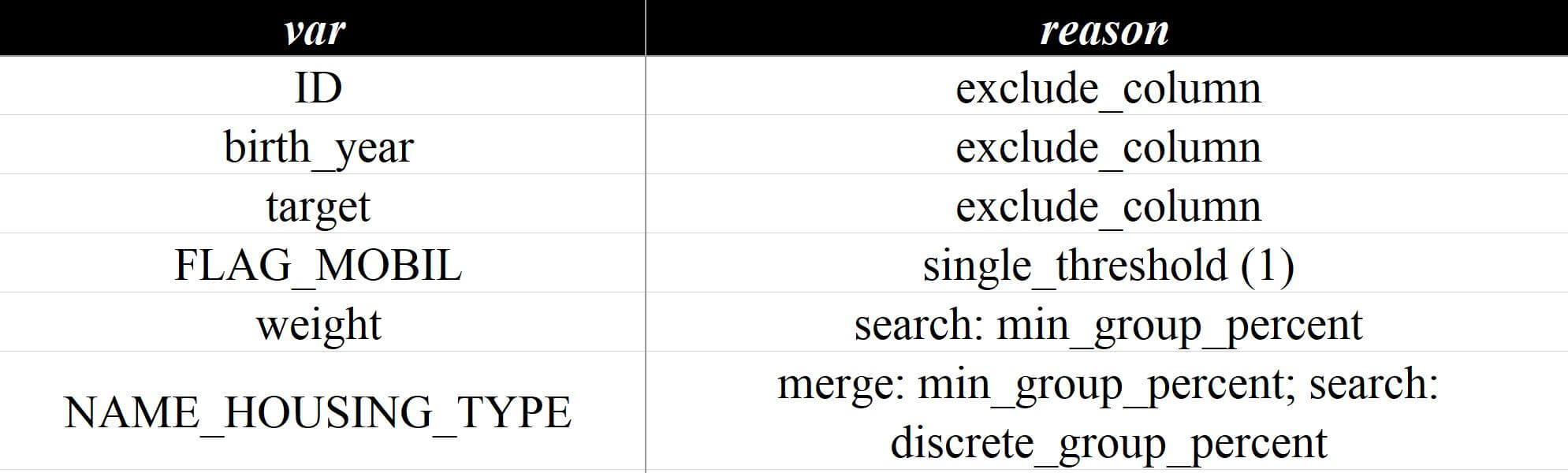
变量"NAME_HOUSING_TYPE"是因为在分箱过滤中被排除,这个后面再展开,简单看一下"FLAG_EMAIL"的取值和分布:
这个指标的取值只有0和1,而且其中0的占比在90%+,而默认是按0.85过滤所以之前会被排除
4.3 离散值过滤
虽然后面会有一些应用与离散值的分箱算法和过滤条件,但一般来说还是会对离散值做一次基本的唯一值过滤,逻辑内核是需要在分箱时自动合并处理的离散值的唯一值应该在一个合理的区间内,目前设定的参数如下:
# 离散值筛选相关
# min_discrete_num 选填,默认1,支持的离散类型变量的唯一值的下限的个数
# max_discrete_num 选填,默认100,支持的离散类型变量的唯一值的上限的个数比如我输入:
at.Analysis.data_flow(
df_train, "./数据分析demo/vy/vy.xlsx", test_data=df_test, response="target",
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
max_discrete_num=15, auto_discrete_max=10, # 同时调低最大离散值和最大合并离散值上限
)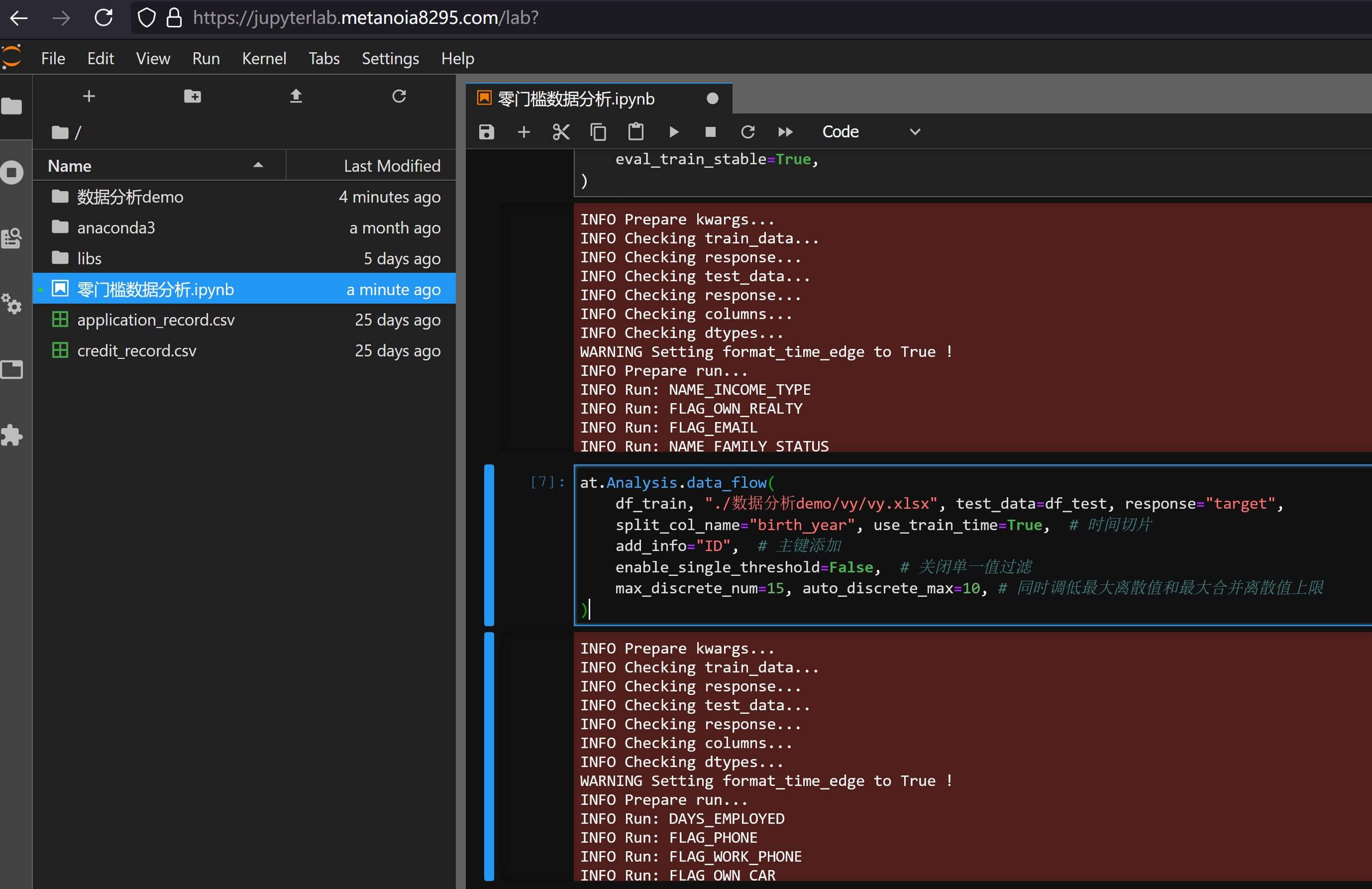
则可以在报告数据分析报告vy.xlsx的变量评估 - 排除详情页面中看到OCCUPATION_TYPE被正确排除:
4.4 信息量筛选
一般来说IV大于0.02才算是有效的数据,即使要算上弱变量互补也不建议IV低于0.01,而从上面的分析汇总环节可以发现很多指标的IV是接近于0的,这里介绍一下过滤的参数:
# 信息量筛选相关
# enable_iv_limit 选填,默认False,是否根据iv阈值筛选变量
# enable_iv_rank 选填,默认True,是否根据iv排序来筛选变量
# iv_threshold 选填,默认[0.02, inf],iv阈值筛选时的上下限
# keep_iv_num 选填,默认2000,按iv排序后,保留的变量的个数
# keep_inf_iv 选填,默认False,在计算iv时,是否保留inf取值默认只开启了enable_iv_rank,取值是2000是因为之前有用过来处理数万个指标,指标数量少的话可以都保留,下面启用阈值过滤,这个数据集质量一般般,先按下限0.01来启用过滤:
at.Analysis.data_flow(
df_train, "./数据分析demo/v7/v7.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 启用iv过滤
)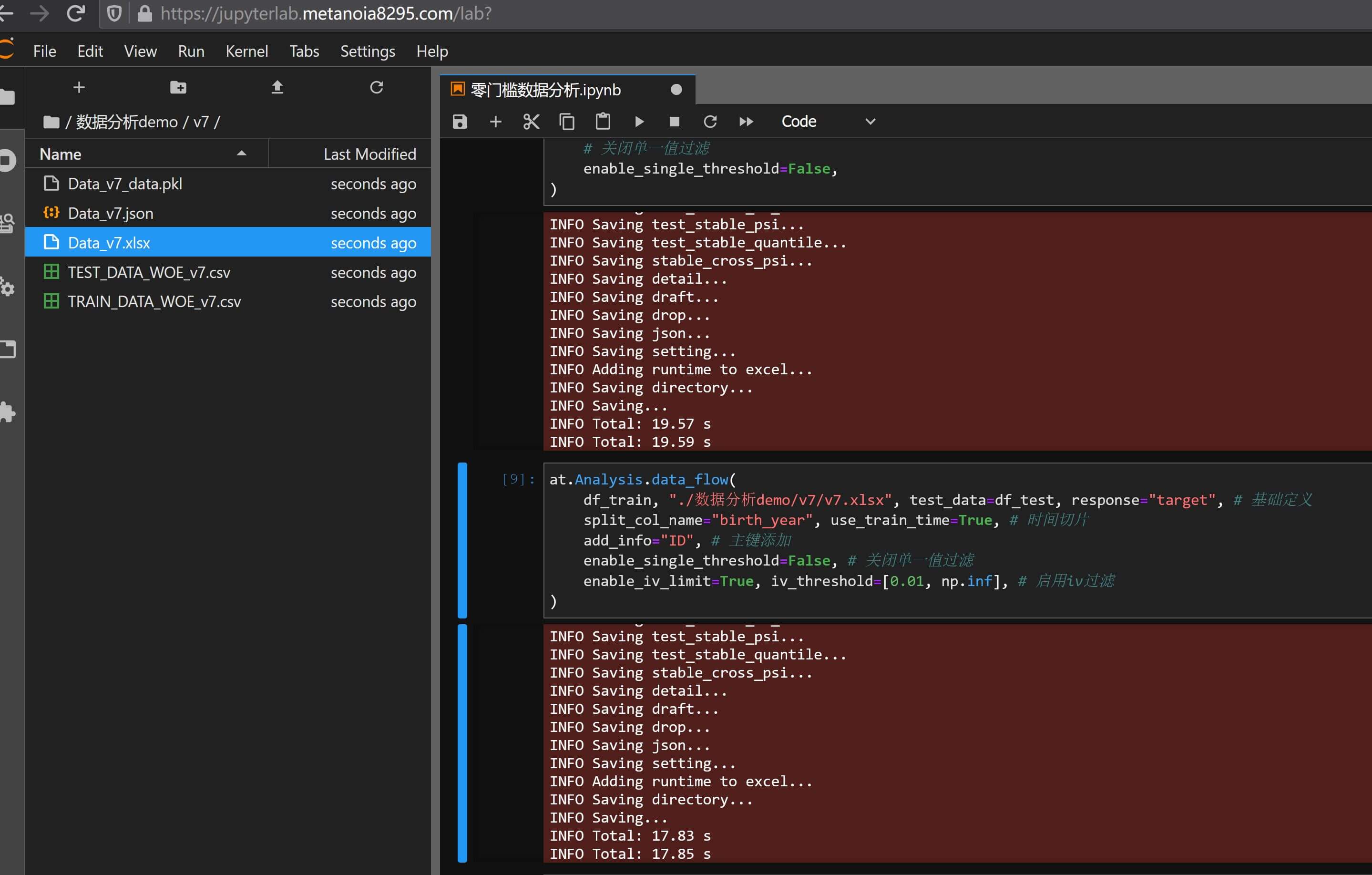
生成报告数据分析报告v7.xlsx,这个时候再来看变量评估 - 分析汇总和变量评估 - 排除详情这两页:
可以看到IV太低的指标已经被正确的移除,并在变量评估 - 排除详情页面中有所提示和展现,做数据分析和模型分析的时候,很多指标IV低可能并不是真的因为这个数据源数据质量差,很有可能是因为采样有篇,而采样有篇既有可能是因为客群定位的问题,也有可能是因为前置的数据过滤问题,这里不再具体展开描述了
4.5 稳定性筛选
稳定性筛选的参数非常多,而且一般来说默认都是不开启筛选和过滤的,因为稳定性太容易受到因素影响导致波动显著,过滤的主要参数如下:
# 训练数据稳定性相关
# select_train_base 选填,默认"min",可选"max"或自定义基准
# eval_train_stable 选填,默认False,是否评估训练数据稳定性
# iv_gap_ratio_train 选填,默认0.5,训练数据iv最大偏移的上限
# ks_gap_ratio_train 选填,默认0.3,训练数据ks最大偏移的上限
# mean_cross_psi_train 选填,默认0.1,训练数据psi平均偏移上限值
# max_percent_gap_train 选填,默认0.1,训练占比的差值筛选的上限值
# monotonic_cnt_rate_train 选填,默认0.5,训练数据单调次数占比的下限值
# mean_quantile_variation_train 选填,默认inf,训练数据的变异系数的上限值
# 测试数据稳定性相关
# select_test_base 选填,默认"min",可选"max"或自定义基准
# eval_test_stable 选填,默认False,是否评估测试数据稳定性
# iv_gap_ratio_test 选填,默认0.5,测试数据iv最大偏移的上限
# ks_gap_ratio_test 选填,默认0.3,测试数据ks最大偏移的上限
# mean_cross_psi_test 选填,默认0.1,测试数据psi平均偏移上限值
# max_percent_gap_test 选填,默认0.1,测试占比的差值筛选的上限值
# monotonic_cnt_rate_test 选填,默认0.5,测试数据单调次数占比的下限值
# mean_quantile_variation_test 选填,默认inf,测试数据的变异系数的上限值
# 训练测试数据稳定性相关
# eval_cross_stable 选填,默认False,评估训练测试稳定性
# iv_gap_train_test 选填,默认0.2,训练测试iv偏移绝对值
# ks_gap_train_test 选填,默认0.1,训练测试ks偏移绝对值
# check_test_monotonic 选填,默认False,检测训练测试单调一致
# train_test_total_psi 选填,默认0.1,训练测试整体对比筛选psi
# train_test_cross_psi 选填,默认0.1,训练测试切片对比平均psi
# max_percent_gap_total 选填,默认0.1,训练测试整体占比偏移上线
# max_percent_gap_cross 选填,默认0.1,训练测试切片占比偏移上线
# train_test_iv_gap_ratio 选填,默认0.5,训练测试数据的iv偏移上限
# train_test_ks_gap_ratio 选填,默认0.3,训练测试数据的ks偏移上限过滤分别从三个维度开发、验证、开发验证对比来进行过滤,并基于分布稳定性和有效性稳定性两个方面展开,稳定性指标可以在页面变量评估 - 分析汇总和页面变量评估 - 稳定性汇总中查看,
一般来说,如果发现有些指标缺失值分布异常导致波动性非常大的情况,常见的处理方式是研究数据背后的原因,把缺失值按业务情况合理化处理,比如在上文中发现的职业的缺失率在年龄分布上有不均衡聚集的现象,
因为使用了birth_year做数据切片,假设现在就用参数过滤来排除业务含义上明显存在关联而导致异常波动的数据(DAYS_BIRTH和Age),则输入:
at.Analysis.data_flow(
df_train, "./数据分析demo/v8/v8.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
# 只启用 mean_cross_psi_train 过滤
eval_train_stable=True, mean_cross_psi_train=5,
iv_gap_ratio_train=np.inf, ks_gap_ratio_train=np.inf,
max_percent_gap_train=np.inf, monotonic_cnt_rate_train=0,
)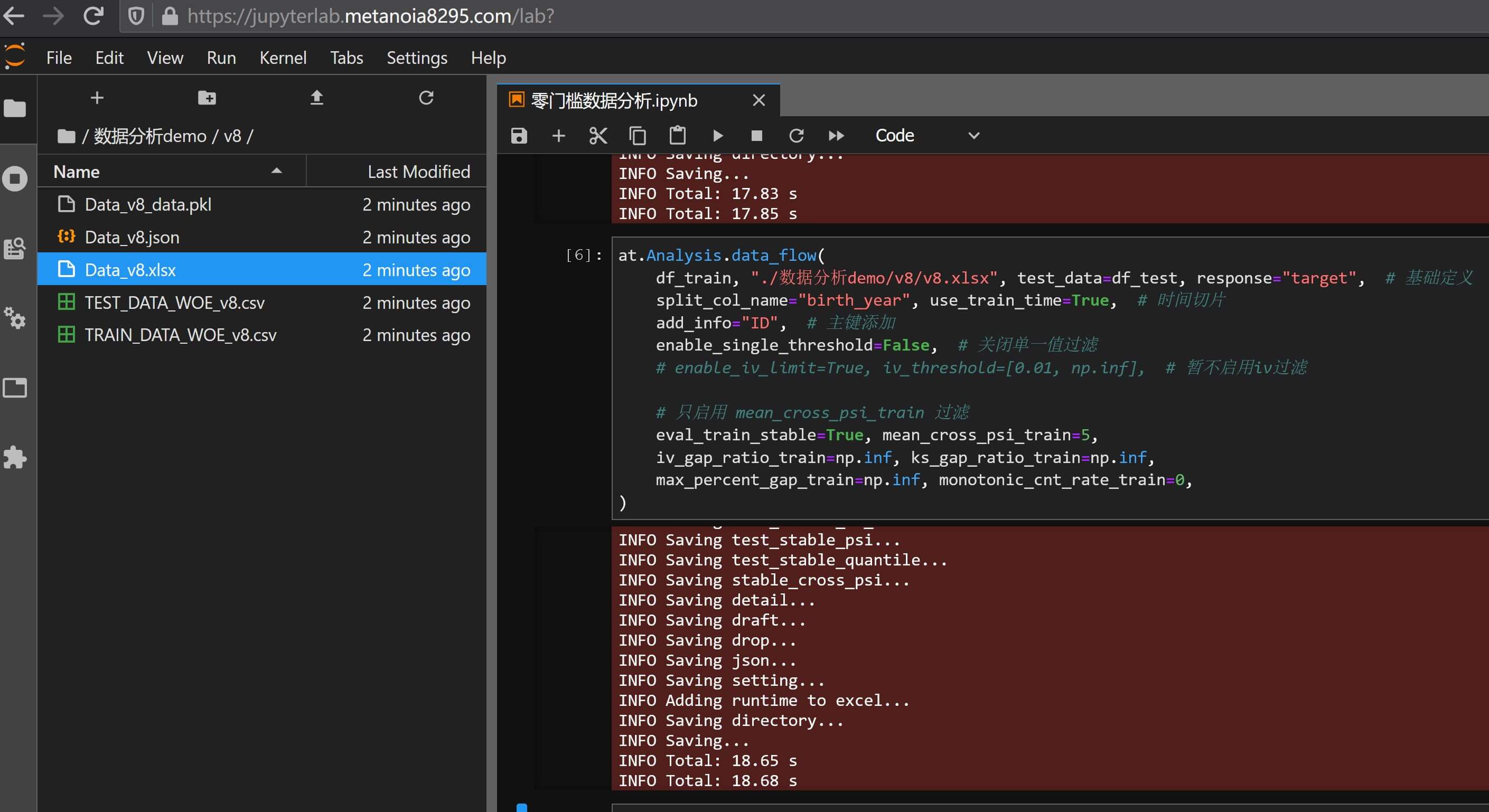
mean_cross_psi_train)
可以看到完美按预期过滤了DAYS_BIRTH和Age这两个指标,具体可以看数据分析报告v8.xlsx这个文件,
目前设置的稳定性过滤阈值都较为严格,如果不经修改直接启用,则很有可能会导致所有数据都被过滤的现象,比如使用:
at.Analysis.data_flow(
df_train, "./数据分析demo/v9/v9.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
# 按预设严格过滤
eval_train_stable=True,
)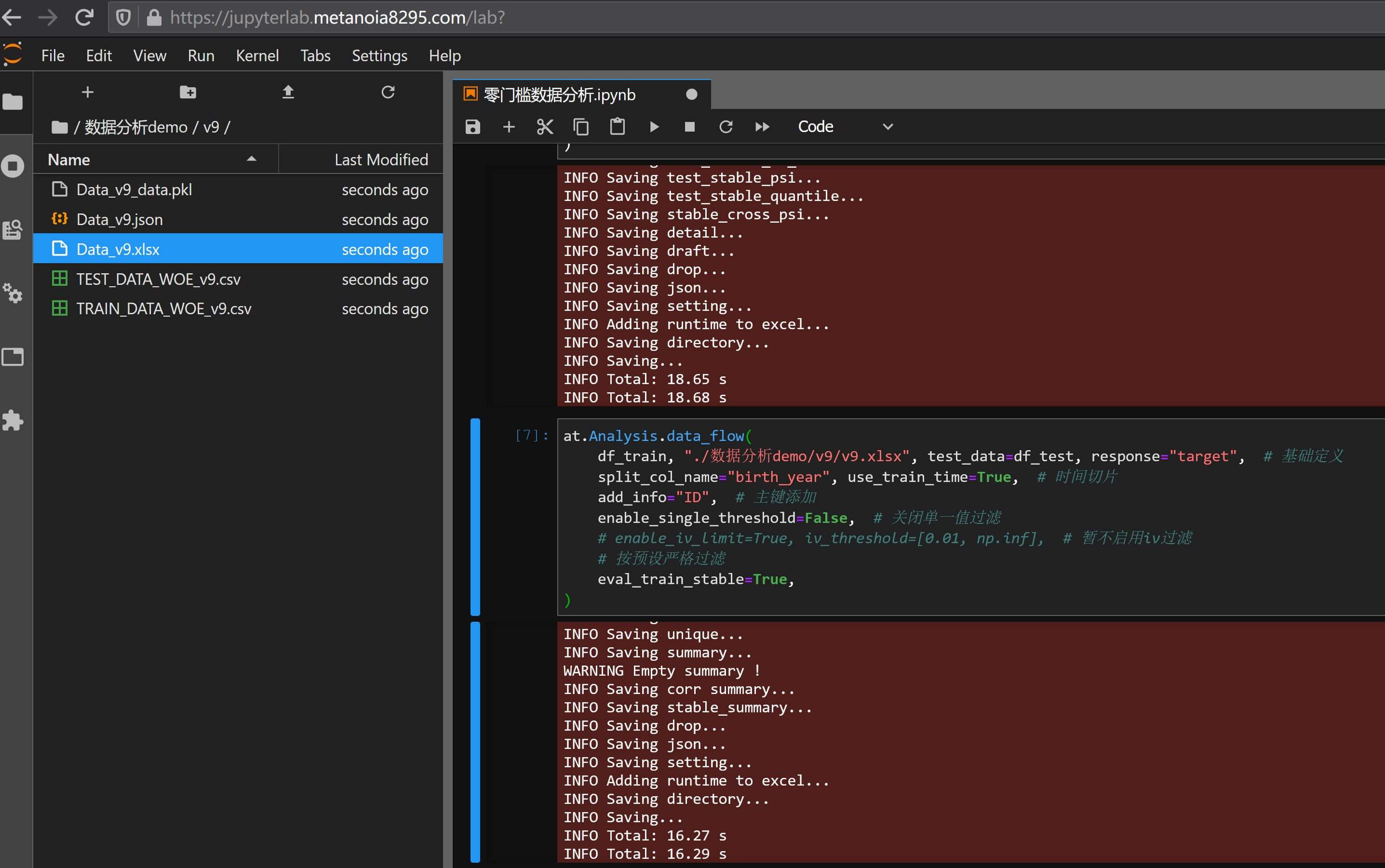
默认)则会在报告数据分析报告v9.xlsx中发现很多页面都消失了:

不过不用紧张,还是可以在变量评估 - 排除详情页面找到这些变量和被排除的原因: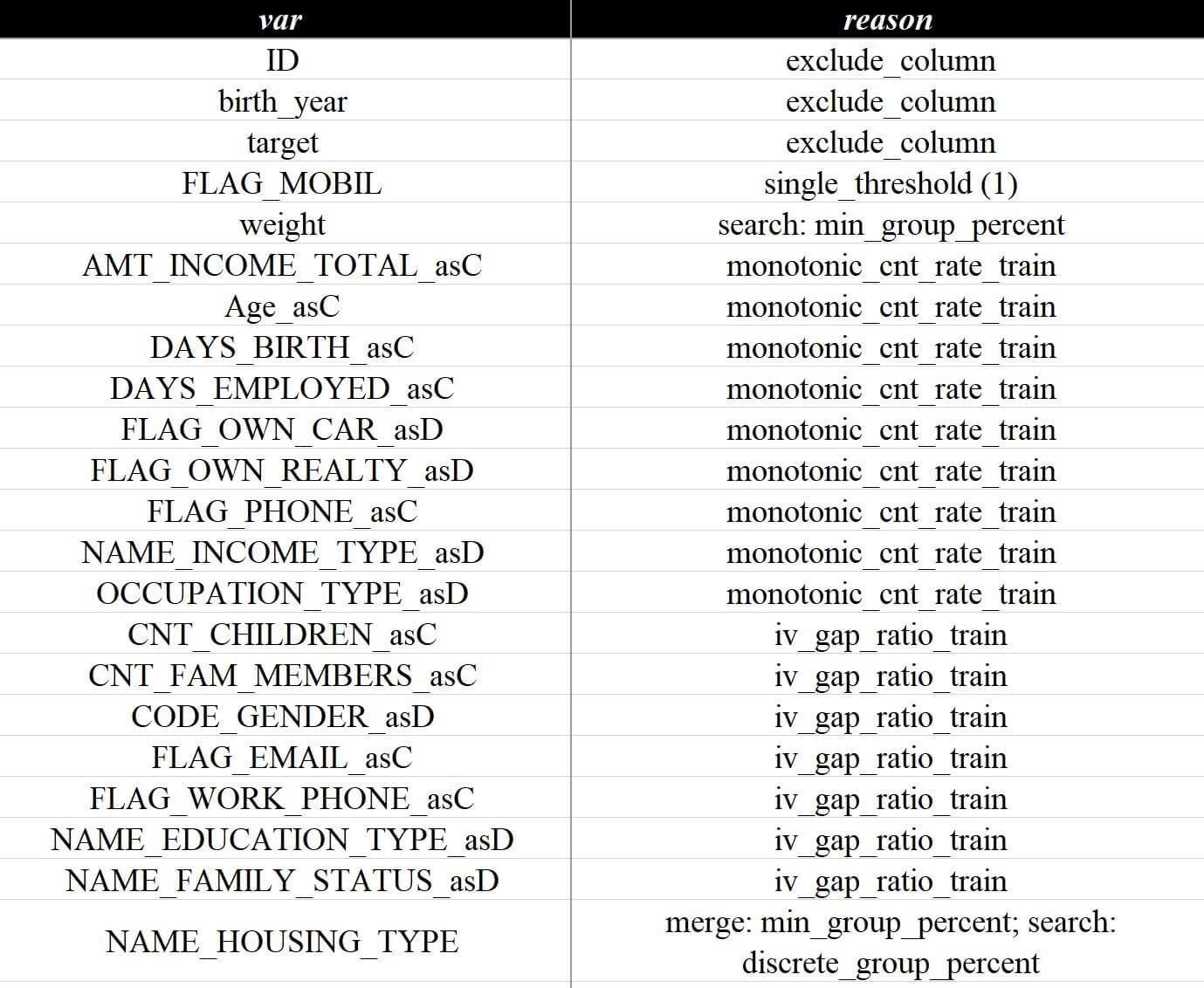
这样就可以进一步微调参数来动态控制稳定性筛选变量范围,不过一般建议不开启稳定性筛选(默认),因为最佳实践还是要从业务源头了解数据成因,只调参数有可能会陷入技术细节而忽略业务真实情况
5 分箱生成和搜索
5.1 概述
分箱可以在变量评估 - 分组详情和变量评估 - 细分详情这两页查看相关信息,这里指标从上到下的排列展示顺序是和页面变量评估 - 分析汇总中的顺序是完全一致的: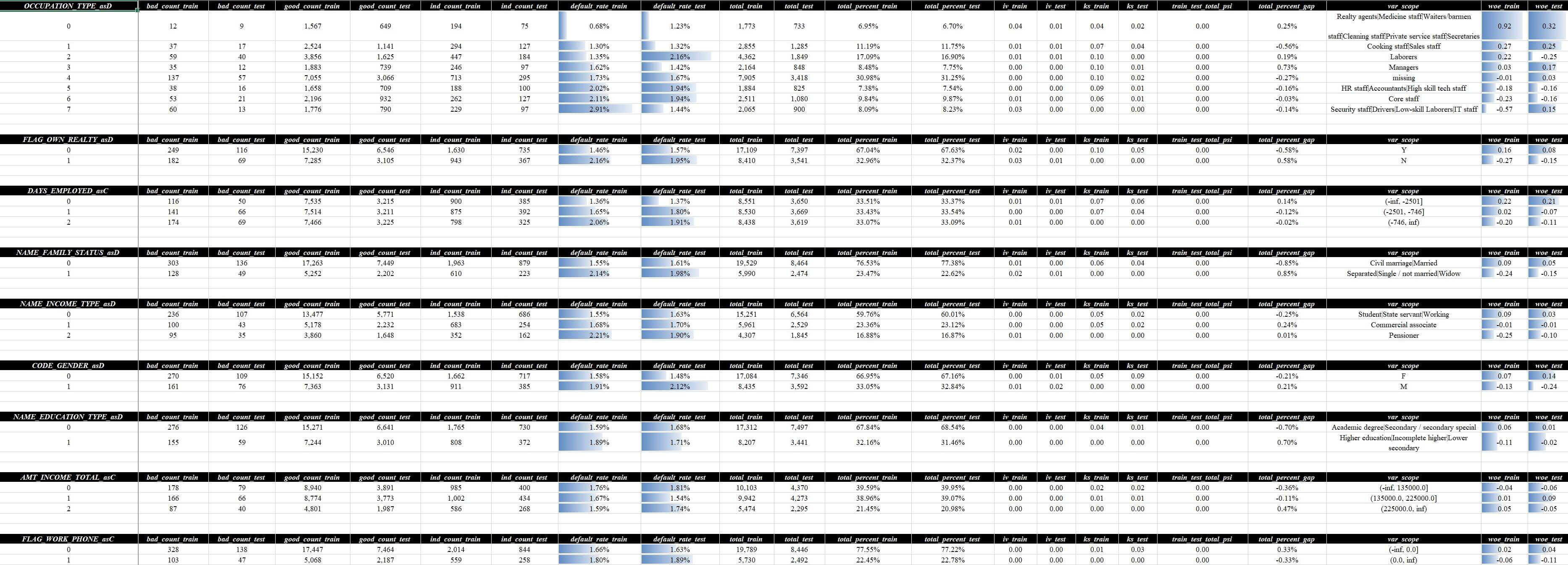
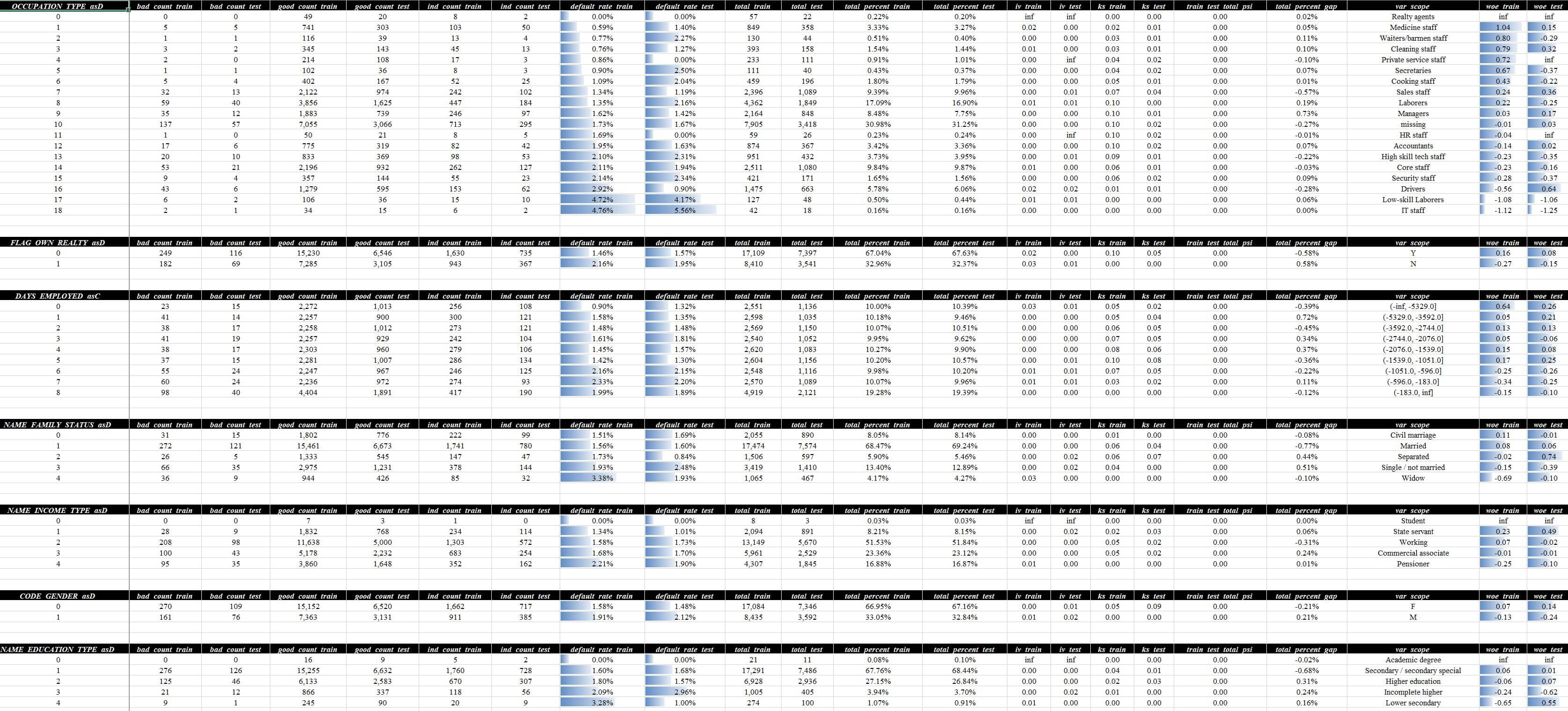
这两页的差异在于,变量评估 - 分组详情页是基于指定分箱算法和搜索条件自动生成,而变量评估 - 细分详情页展示了设定范围内尽可能细颗粒度的分箱结果,这两页都会自动拼接train/test两个数据维度的结果,
页面展示上涉及可调整的参数有:
# 输出相关
# var_range 选填,默认["-inf", "inf"],展示最小最大值
# add_ind_ks 选填,默认False,计算将不确定值视为good的ks数值
# add_cum_info 选填,默认False,是否在表中展示累计个数与累计占比
# add_cum_odds 选填,默认False,是否在结果表中展示累计好坏客户比
# add_cap_info 选填,默认False,是否在表中展示组内占比的百分比列
# add_cum_left 选填,默认False,是否在表中展示累计与剩余目标占比
# add_gini_lift 选填,默认False,是否在表中展示gini和lift的计算值
# save_draft_table 选填,默认True,True时输出参数范围内的最大分组数做参考这一章节会按分箱算法和生成、离散值分箱生成、手动指定分箱、半自动分箱生成、分箱搜索和过滤、WOE取值优化这几个部分逐一展开
5.2 分箱算法和生成
分箱算法是一个非常大的话题,这里长话短说,根据有无使用response的信息笼统分类为有监督学习和无监督学习,
举例来说,我使用分位数做为分割点进行分箱没有使用到response的信息就是无监督学习,又比如我用x和y训练了决策树并使用决策树的分割点做为分箱点就是有监督学习,
实战中分箱算法的一大难点在于如何选择,不过这里我基本上把市面上常见的分箱算法都高性能嵌入或重写了,实战中按需调用多次尝试对比即可,有需要后期可持续扩展算法包,目前涉及到的参数主要有:
# 数值变量分组生成相关
# precision 选填,默认3,处理过程中,保留的小数点数
# cut_method 选填,默认"cumsum",参考"data_binning_mode"
# max_cut_part 选填,默认10,分组可能的最大数量,建议小于20
# include_right 选填,默认True,数值分组时的边界,默认含右侧值
# tree_splitter 选填,默认"best",可选"random","tree"分箱参数
# tree_criterion 选填,默认"gini",可选"entropy","tree"分箱参数
# best_search_depth 选填,默认3,最优搜索时的最大深度/次数,建议小于5
# best_path_generate 选填,默认"tree",按树路径生成,或"combinations"遍历
# supervised_tree_cumsum 选填,默认False,在tree分箱时使用enable_supervised_cumsum
# supervised_kmeans_cumsum 选填,默认True,在kmeans分箱时使用enable_supervised_cumsum
# enable_supervised_cumsum 选填,默认True,按min_group_percent基于透视表对监督搜索预分组
# continuous_discrete_limit 选填,默认1,当数值型变量唯一取值小于等于该值时,按离散值处理数值型变量其中当cut_method为"kmeans"时,额外涉及的参数如下:
# kmeans分箱参数
# enable_kmeans_mini 选填,默认True,启用MiniBatchKMeans替换传统KMeans算法
# kmeans_init_method 选填,默认"k-means++",可选"random",kmeans初始化参数
# kmeans_mini_number 选填,默认100,启用enable_kmeans_mini时的batch_size值
# kmeans_init_number 选填,默认6,传统KMeans和MiniBatchKMeans算法的含义不同
# kmeans_max_iterint 选填,默认200,防止不收敛,到达最大迭代次数后算法就终止
# kmeans_random_state 选填,默认0,算法中心初始化时的随机种子,取值为int/None
# enable_mini_tol_value 选填,默认False,在mini时启用kmeans_tolerance_value检测
# kmeans_tolerance_value 选填,默认0.0001,容忍最小误差,当误差小于取值算法会终止
# kmeans_mno_improvement 选填,默认10,使用MiniBatchKMeans时候的max_no_improvement
# kmeans_mini_init_number 选填,默认None,为3*batch_size,需要大于n_clusters(max_cut_part-1)
# kmeans_reassignment_ratio 选填,默认0.01,某个类别质心被重新赋值的最大次数比例,增大会提升收敛时长
# kmeans_auto_omp_num_threads 选填,默认True,在win的MiniBatchKMeans时调整OMP_NUM_THREADS为1避免内存溢出以上参数主要用来进行分箱生成,支持的算法如下:
| 类别 | 数量 | 算法 |
|---|---|---|
| 无监督 | 循环搜索区间:[2 , max_cut_part],按每个点设定分组数 | linspace, cumsum, quantile, kmeans |
| 有监督 | 按best_search_depth为深度,递归搜索最优点,每条路径一个分组,当best_path_generate为"combinations"时则排列组合节点生成分组 | best-ks, tree, chi-merge, rate-merge |
每个算法的概述和备注如下:
| 算法 | 概述 | 备注 |
|---|---|---|
| linspace | 按给定分组数,从最小值到最大值等步长切割,取切割后的点做为分割点 | 参考np.linspace |
| cumsum | 按给定分组数(例:4 -> 25%)为阈值,取排序累加满足阈值的每个点做为分割点 | 对比quantile,确保每组数量占比一定>=给定的阈值 |
| quantile | 按给定分组数求数据分位数,取分位数点做为分割点 | 参考np.quantile |
| kmeans | 按给定分组数使用kmeans算法进行聚类,取聚类中心点取值做为分割点 | 底层基于sklearn.cluster.KMeans.和sklearn.cluster.MiniBatchKMeans实现,默认开启supervised_kmeans_cumsum |
| best-ks | 按给定深度,递归求解每层深度上的最大KS对应的数据点,按搜索路径或节点排列组合为分割点 | 底层基于常见的best ks算法进行优化改进,默认开启enable_supervised_cumsum |
| tree | 按给定深度,使用决策树进行搜索,按搜索路径或节点排列组合为分割点 | 底层基于sklearn.tree.DecisionTreeClassifier实现,默认关联min_group_percent,默认关闭supervised_tree_cumsum |
| chi-merge | 按给定深度,取卡方最大值分割数据,递归搜索,按搜索路径或节点排列组合为分割点 | 底层基于常见的卡方分箱算法进行优化改进,默认开启enable_supervised_cumsum |
| rate-merge | 按给定深度,基于逾期率差值最大值进行数据分割,递归搜索,按搜索路径或节点排列组合为分割点 | 参考卡方分箱思想,基于自定义极值分割,默认开启enable_supervised_cumsum |
这些算法中,监督学习的算法,如:chi-merge、best-ks、rate-merge等,都是默认启用enable_supervised_cumsum进行预分组优化,并基于预排序生成的pivot_table进行分割点计算,在获取有监督学习性能的同时通过控制分组数量占比尽量避免过拟合的情况发生,
cut_method这里的默认值是cumsum是因为数据才是效果的上限,而且在搭配搜索算法后效果上一般也足够用了,举例来说我用默认参数获取的数据结果和Kaggle中最高vote的code的答案计算得到的IV差不多都在一个区间内,并没有特别显著的差异,参考如下: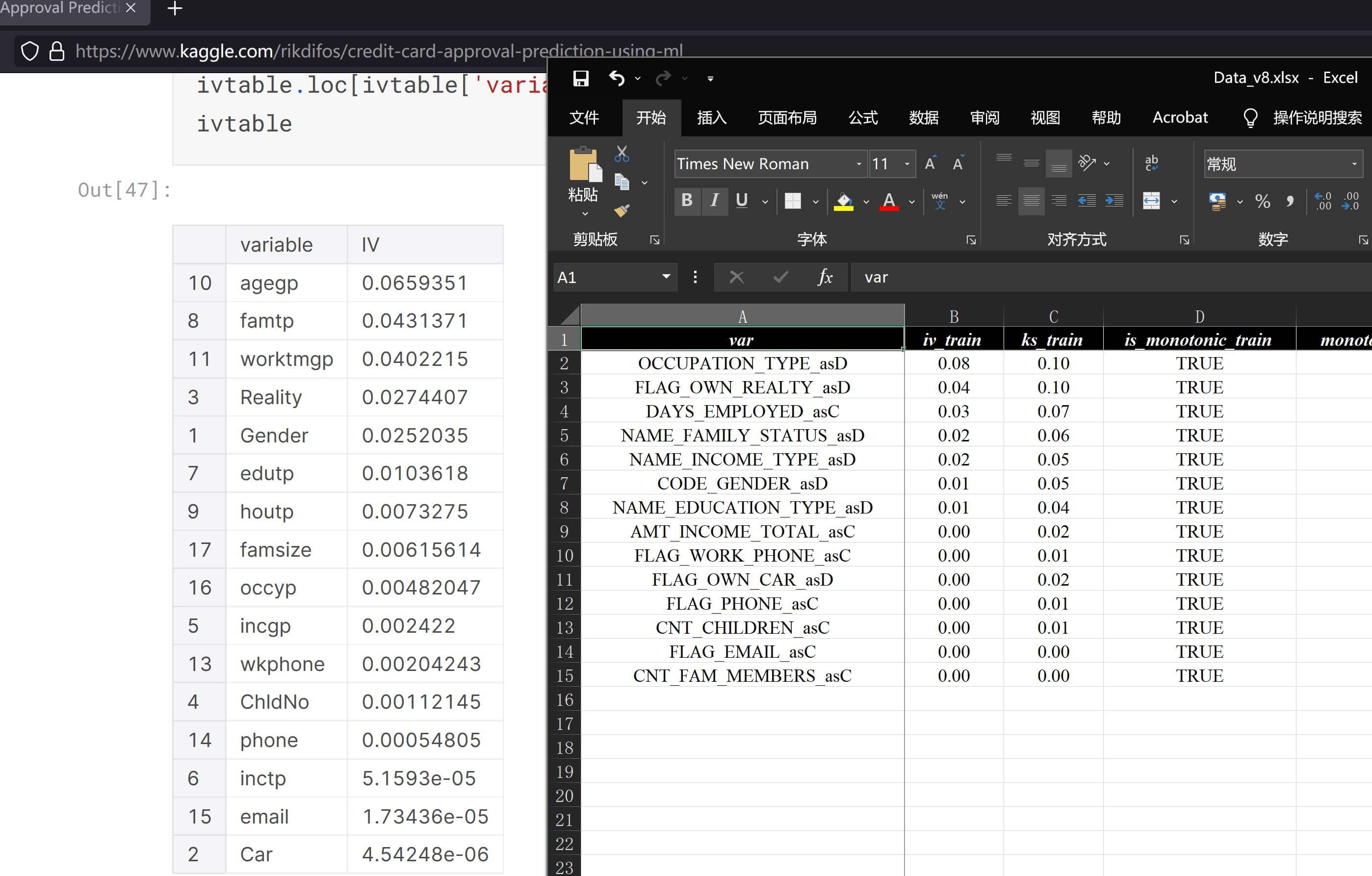
从上面的图来看,按经验简单推断,即使基于分箱算法调参,估计不同算法之间差异也不会太离谱,这里花几分钟把上面列出的算法全部运行了一下,大概可以这样写:
for i in (
"linspace", "cumsum", "quantile", "kmeans", "best-ks", "tree", "chi-merge", "rate-merge",
):
at.Analysis.data_flow(
df_train, "./数据分析demo/v9-%s/v9-%s.xlsx" % (i, i), test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
exclude_column=["ID", "weight"], # 排除权重
cut_method=i
)不过我还是展开写了,这样可以看到每个输出的耗时,数据量小的时候计算层面的性能差异非常小:
具体的算法样例报告可以从下面的链接下载:
这么多报告当然不能人工肉眼比较,这里自动化生成好了一份汇总报告数据分析报告v9-算法对比.xlsx,这个报告如何自动生成可以参考后面章节6.5 报告合并与数据合并,这里直接看对比结果: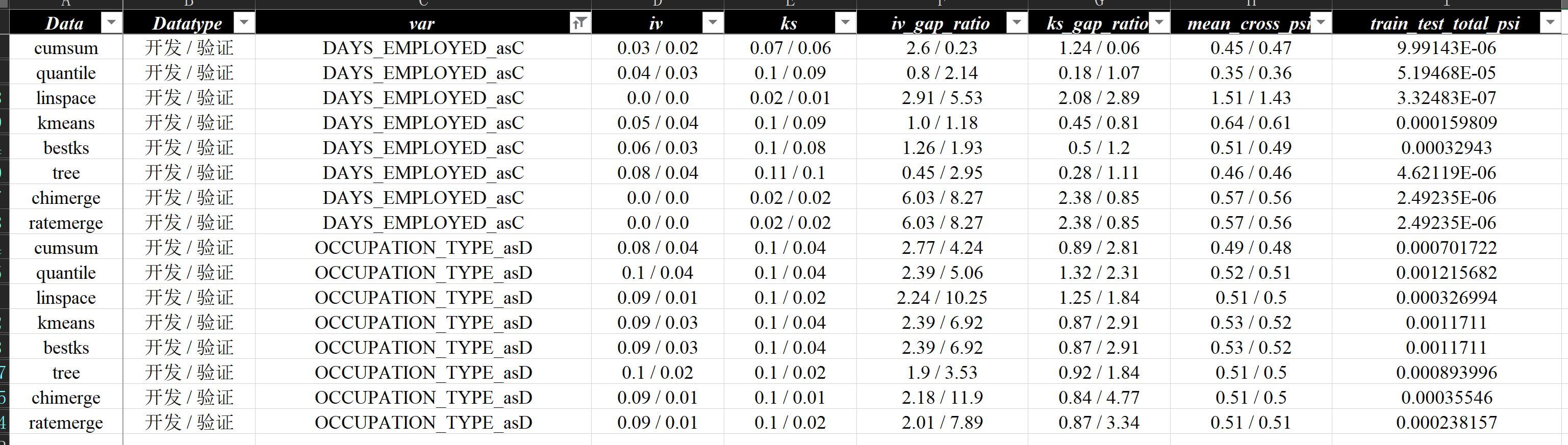
DAYS_EMPLOYED、OCCUPATION_TYPE)
上面的对比图的效果值是按train / test来展示的,从上图可以解读出很多有意思但并不一定总是成立的点:
有监督学习效果比无监督学习更好的概率更大一些- 但同时
有监督学习衰减也会比无监督学习更快,更不稳定 - 但
有监督学习衰减后的效果还是有可能比无监督学习更好 - 并不是所有的
有监督学习算法的效果都总是好于无监督学习 - 不同算法之间效果波动仍然在同一范围内
iv <= 0.1,数据仍是效果上限
另外,细心的朋友可以观察到上面有一个include_right的参数,这是为了防止有人抬杠说我就喜欢分箱左闭右开怎么不能支持,参考用例如下:
at.Analysis.data_flow(
df_train, "./数据分析demo/v9-left/v9-left.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
include_right=False, # 分箱展示调整为左闭右开
)结果可以查看报告数据分析报告v9-left.xlsx,看一下和数据分析报告v9-cumsum.xlsx这一份的对比图,汇总页是完全一样的: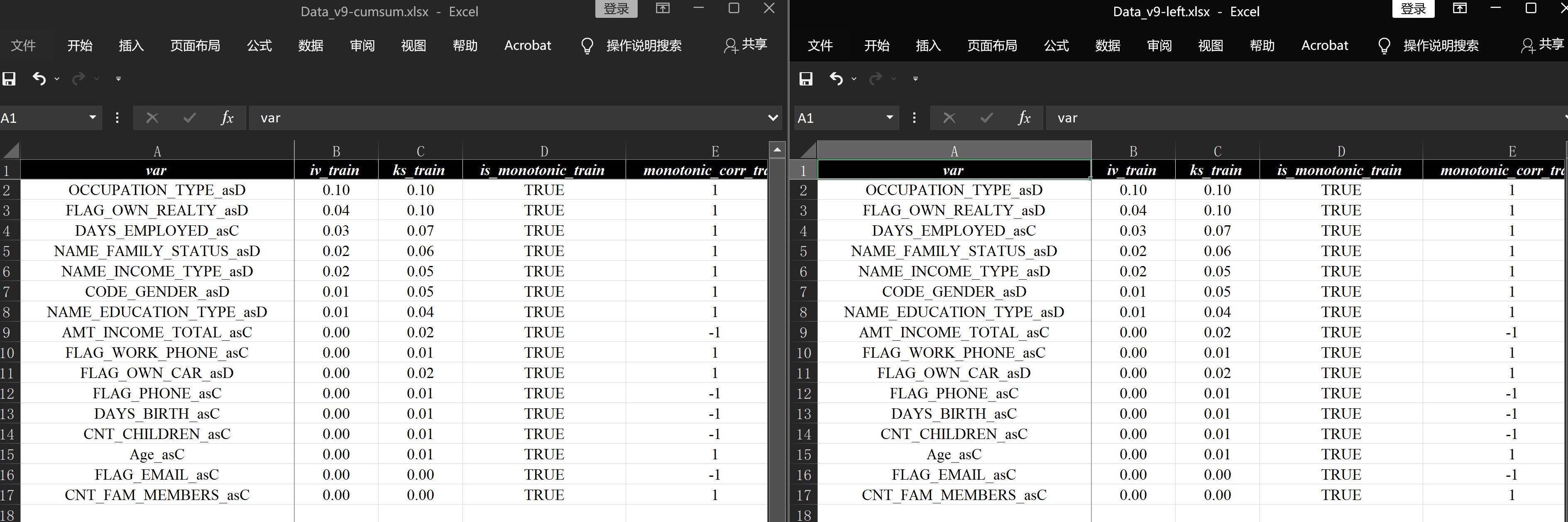
再看详情页,除了展示的分割点对应错位以外的的信息全是一样的,其实底层的分割点是一致的,只是展示上的差异: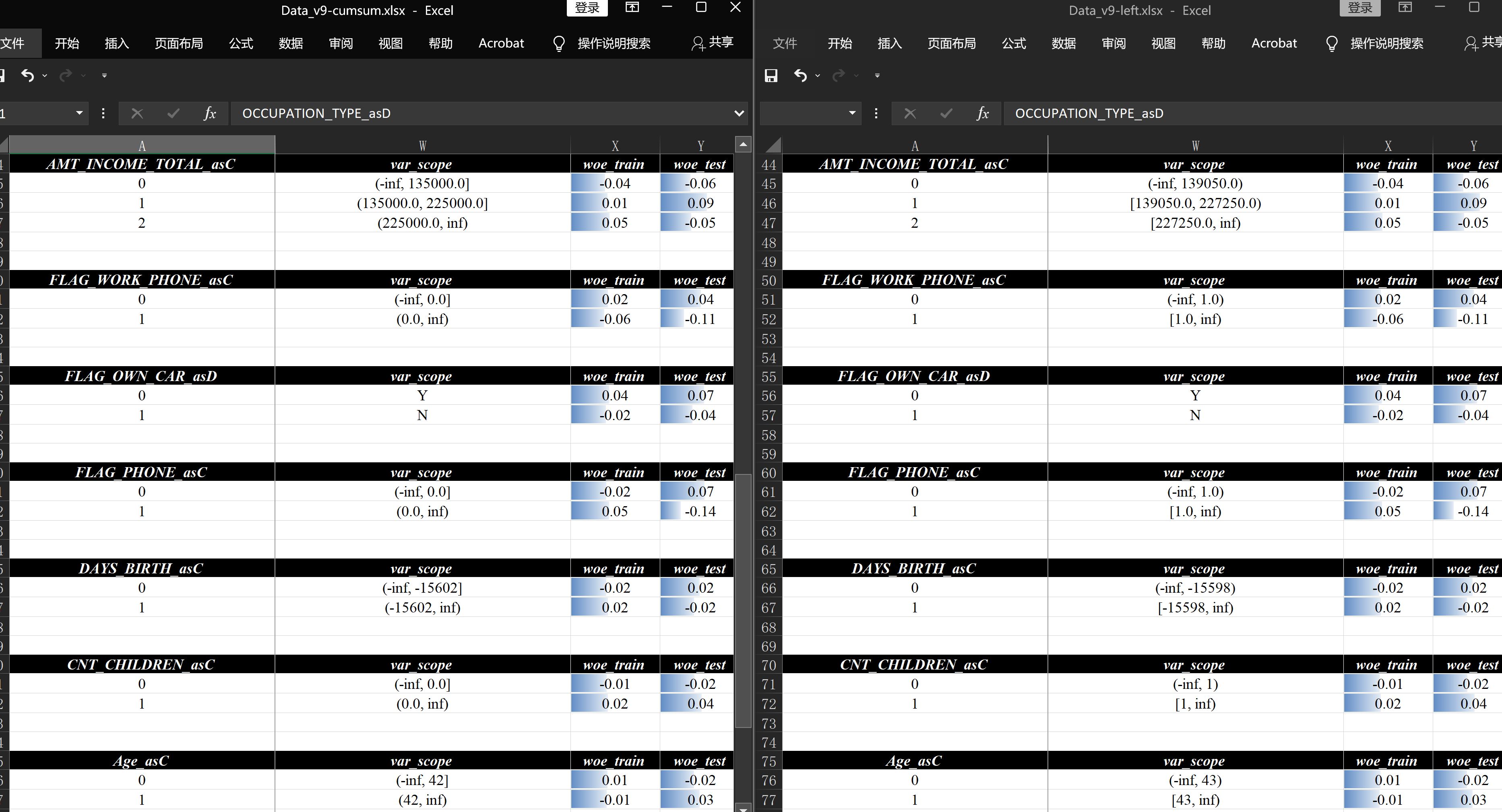
5.3 离散值分箱生成
在业界和学界,离散值如何进行分箱处理一直是一个非常流行的问题,从上一节来看这些算法都是针对数值型变量的,甚至sklearn.tree.DecisionTreeClassifier按文档来看都是不支持离散值的,那么如何处理离散值呢?
离散值和数值对比,本质的差异在于离散值的无序性,数值变量天然具有排序性所以可以按算法应用,顺着这个思路,我实现的处理逻辑是预先把离散值从无序映射成有序,然后就可以直接应用上述章节中数值变量才能使用的算法,获取到分割点后再映射回离散值即可,具体参数如下:
# 离散变量分组生成相关
# auto_discrete_min 选填,默认3,自动合并离散值的下限,小于该值不会被合并
# auto_discrete_max 选填,默认50,自动合并离散值的上限,太大会导致内存溢出
# auto_nan_discrete 选填,默认None,自动添加pd._libs.parsers.STR_NA_VALUES和缺失
# sort_discrete_rank 选填,默认True,在展示离散值分组结果时,是否按趋势进行排序展示
# auto_merge_discrete 选填,默认True,是否自动合并离散值,启用时按上下限进行算法合并
# merge_discrete_plan 选填,默认"best-rank",或function,参考"data_string_mode"的范围
# discrete_sort_method 选填,默认"woe",可选"rate",离散值在进行预排序和展示时的依据名称默认离散值处理会带有缺失推断,缺失范围是np.NaN和pd._libs.parsers.STR_NA_VALUES,有额外需求入参list到auto_nan_discrete即可,merge_discrete_plan的范围和参数定义如下:
| 排序方式 | 排序概述 | 效果示例 |
|---|---|---|
| “string-sort” | 按字符串进行排序 | a,b,c… |
| “length-sort” | 按长度排序 | a,aa,aaa… |
| “string-length-sort” | 先按长度,再按字符串排序 | a,b,c,aa,bb,cc… |
| “best-rank” | 按逾期率或woe进行排序 | |
| pyfunction | 入参自定义python函数,按函数处理排序 | list_out = pyfunction(list_in) |
比如目前的指标OCCUPATION_TYPE的IV是最高的,主要也是因为默认是基于"best-rank"进行分组合并的,其实比较合理的方式是需要按业务含义进行预先分组,入参方式在下面5.5 手动指定分箱中展开描述
5.4 随机选取分箱算法
上面的案例中,默认是选用一种算法应用用所有指标,这也是较为通用的做法,但偶尔可能也会存在一些局限性,
- 如果数据衍生的维度接近(比如时间切片上的跨度较小),则分析结果如iv等也会非常接近,且这些指标分箱之后的相关性也会较高
- 假如我通过参数切换可选的算法来试图全局对比(类似5.2 分箱算法和生成中的展示),则时间复杂度会按使用算法的范围成倍增加,在海量指标的场景下,即使性能再高,时间成本也异常惊人
这里通过两个参数,来折衷提供尝试缓解上述问题的解决方案,参数如下:
# 变量分组算法随机化
# random_cut 选填,默认False,每个变量随机使用cut_method
# random_method_range 选填,默认None,默认"data_binning_mode",入参list/tuple是的,答案就是随机化,当开启random_cut后会忽略已经设置的cut_method参数,对每个待分析的变量都从可用的分箱算法列表中随机选取一种算法来分析,也可以指定random_method_range来缩小随机化分箱算法的范围,用例如下:
at.Analysis.data_flow(
df_train, "./数据分析demo/v9-random/v9-random.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
random_cut=True, # 启用随机分箱
)在报告数据分析报告v9-random.xlsx的结果中会多一页变量评估 - 分箱算法,会列出每个指标用到的分箱算法,如下:
当然最终随机化的效果和数据本身关系非常大,就这个数据集而言也不太看得出随机化的效果
5.5 手动指定分箱
上面提到一般离散值会提前按业务含义预处理,还是用OCCUPATION_TYPE举例,比如Kaggle有这样处理的:
# https://www.kaggle.com/rikdifos/credit-card-approval-prediction-using-ml
new_data.loc[(new_data['occyp']=='Cleaning staff') | (new_data['occyp']=='Cooking staff') | (new_data['occyp']=='Drivers') | (new_data['occyp']=='Laborers') | (new_data['occyp']=='Low-skill Laborers') | (new_data['occyp']=='Security staff') | (new_data['occyp']=='Waiters/barmen staff'),'occyp']='Laborwk'
new_data.loc[(new_data['occyp']=='Accountants') | (new_data['occyp']=='Core staff') | (new_data['occyp']=='HR staff') | (new_data['occyp']=='Medicine staff') | (new_data['occyp']=='Private service staff') | (new_data['occyp']=='Realty agents') | (new_data['occyp']=='Sales staff') | (new_data['occyp']=='Secretaries'),'occyp']='officewk'
new_data.loc[(new_data['occyp']=='Managers') | (new_data['occyp']=='High skill tech staff') | (new_data['occyp']=='IT staff'),'occyp']='hightecwk'按业务来看分类的逻辑还算是合理的,不过这哥们写得太繁琐了,这里来介绍一下自定义分组,
# 自定义变量分组
# customized_groups 选填,默认{},设{变量str: 输出格式list}来定制分组就按上面那个例子我们转换一下,离散值自定义用|隔开,数值变量直接定义分割点即可:
at.Analysis.data_flow(
df_train, "./数据分析demo/v10/v10.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
customized_groups={
"OCCUPATION_TYPE": [
"Cleaning staff|Cooking staff|Drivers|Laborers|Low-skill Laborers|Security staff|Waiters/barmen staff",
"Accountants|Core staff|HR staff|Medicine staff|Private service staff|Realty agents|Sales staff|Secretaries",
"Managers|High skill tech staff|IT staff",
],
"CNT_CHILDREN": [-np.inf, 0, np.inf],
}
)
可以在文件数据分析报告v10.xlsx中的变量评估 - 分组详情看到结果:
OCCUPATION_TYPE)
按业务含义合并后,这个指标整体IV马上就降下来了,这又是一个典型的业务vs算法的差异点
- 缺失和缺失推断值都会被设置为单独一组(如果需要填充或合并请提前处理数据)
- 未在设置中列明的值会被自动合并单独形成一组(针对离散值)
- 自定义分箱会直接穿透成结果展示,不会再经过其他过滤和筛选
- 离散值本身不能包含
|、'、"等,不然会报错提醒 - 数值变量自定义分箱必须左右全包含,建议
-np.inf开头np.inf结尾,不然会报错提醒
5.6 半自动分箱生成
是的你没有看错,底层计算模块支持半自动分箱生成,通过指定一个或多个特殊值单独一组的模式,可以进行有选择范围内的分箱算法生成,实现半自动分箱生成,具体入参如下:
# 分组搜索排除相关
# keep_separate_value 选填,默认None,因各种原因需要单独一组的数,支持str/int/float/list
# optimal_separate_woe 选填,默认True,启用时针对separate启用和缺失值一样的WOE优化处理
# check_separate_value 选填,默认False,是否对separate取值直接生成的分组进行自动化检测
# check_separate_nearby 选填,默认True,是否对separate取值关联生成的分组进行自动化检测
# group_include_separate 选填,默认True,min_group_percent百分比是否包含separate的权重- 支持单值输入,全局生效,如
keep_separate_value=0或keep_separate_value="Student" - 支持
list输入,全局生效,如keep_separate_value=[0, "Student"] - 支持
dict输入,并限定生效的变量范围,如keep_separate_value={"var1": [0, 1], "var2": ["Student"]} - 离散值指定即为单独一组,数值会按保留小数
x位增减 $1^{-x}$ 的值,如3位小数:0->-0.001, 0.001 - 默认输入的值会绕过分箱搜索和检测,需要回归正常检测可开启对应参数,但一般不建议
这里写个简单案例,参考如下:
at.Analysis.data_flow(
df_train, "./数据分析demo/v11/v11.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
customized_groups={
"OCCUPATION_TYPE": [
"Cleaning staff|Cooking staff|Drivers|Laborers|Low-skill Laborers|Security staff|Waiters/barmen staff",
"Accountants|Core staff|HR staff|Medicine staff|Private service staff|Realty agents|Sales staff|Secretaries",
"Managers|High skill tech staff|IT staff",
],
"CNT_CHILDREN": [-np.inf, 0, np.inf],
},
exclude_column=["ID", "weight"], # 排除权重
keep_separate_value=1, # 设置1为单独一组
)
则对比报告数据分析报告v10.xlsx和数据分析报告v11.xlsx中的变量评估 - 分组详情,可以看到: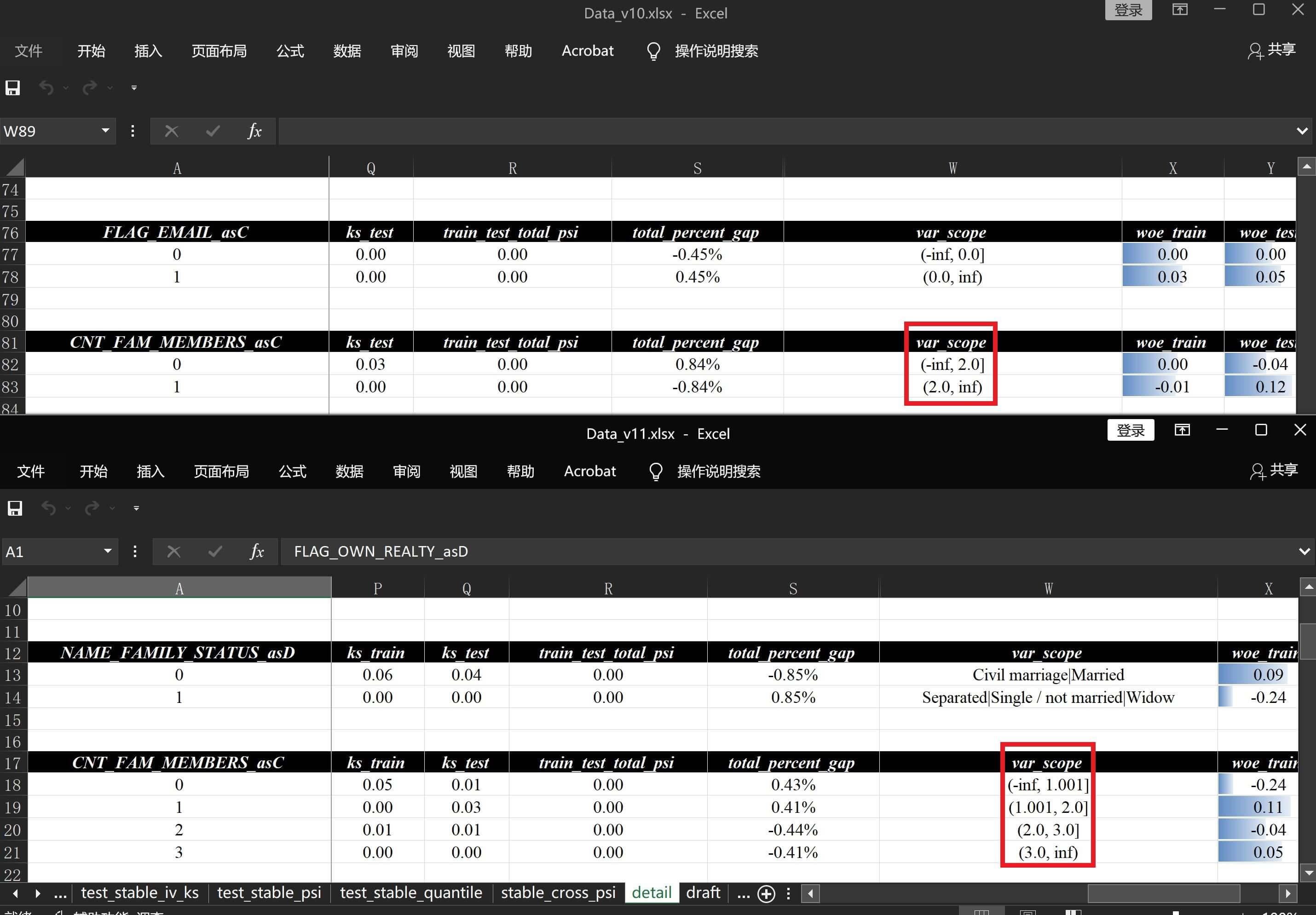
需要单独分组的1被正确的划到了1.001分组内(默认保留3位小数),
简单举例如下,还是上面的案例,我把算法改成"tree",输入:
at.Analysis.data_flow(
df_train, "./数据分析demo/v11-tree/v11-tree.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
customized_groups={
"OCCUPATION_TYPE": [
"Cleaning staff|Cooking staff|Drivers|Laborers|Low-skill Laborers|Security staff|Waiters/barmen staff",
"Accountants|Core staff|HR staff|Medicine staff|Private service staff|Realty agents|Sales staff|Secretaries",
"Managers|High skill tech staff|IT staff",
],
"CNT_CHILDREN": [-np.inf, 0, np.inf],
},
exclude_column=["ID", "weight"], # 排除权重
keep_separate_value=1, # 设置1为单独一组
cut_method="tree", # 调整算法尝试
)来看得到的文件数据分析报告v11-tree.xlsx的结果,会发现很多指标都被排除了: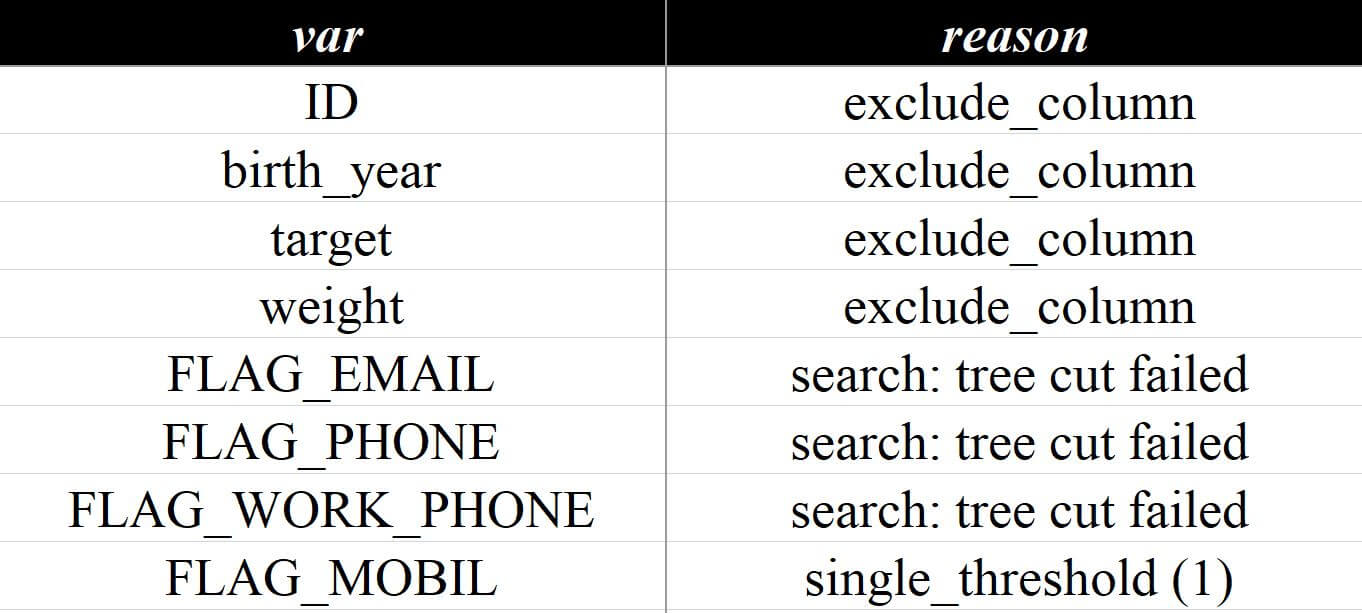
这个的主要原因是因为那些指标基本上都只有01两种取值,在排除了0的情况下,只有1取值的指标是无法进行有监督学习学到分割点的,因此会提示分组失败,而默认的cumsum等无监督学习是可以把唯一取值提取的,所以不会报错,
因此如果启用这个小节的参数,请确保需要单独一组的值在业务含义上足够特殊确实单独一组的必要
5.7 分箱搜索和过滤
整体分箱搜索和过滤上参考了规划求解的思想,在参数化算法生成一系列分箱的基础上,再通过一些约束条件来过滤这些分箱,并根据某个最优条件(例如最大iv)取过滤后的最佳分箱,当然手动指定的分箱是不会经过这一步的,
具体涉及的参数如下:
# 数值变量分组搜索相关
# search_cut 选填,默认True,False时采用算法生成的最后一组
# get_cut_by 选填,默认["len", "ks", "iv"],搜索优先级排序
# random_search 选填,默认False,开启时忽略get_cut_by随机选组
# min_group_num 选填,默认2,分组的最小的保留数量,不包含缺失值
# find_step_num 选填,默认3,判定无效时的额外搜索步数,建议小于5
# find_step_mode 选填,默认False,True时采用有限步数搜索,可能遗漏
# cut_limit_list 选填,默认[20, 5, 3],代表分箱/深度/有限搜索的上限
# min_gap_percent 选填,默认0.00,需要数值,限制组内坏账率差值/坏账率
# min_group_percent 选填,默认0.05,分组后的最小百分占比,仅使用好坏计算
# group_include_none 选填,默认True,min_group_percent百分比是否包含缺失值
# check_monotonicity 选填,默认True,是否对离散化之后的数据进行单调性的检验
# strict_monotonicity 选填,默认True,是否严格单调,不严格时曲线可存在一个凸点
# check_ind_monotonicity 选填,默认True,检查单调性时,单调性计算是否包含不确定客户
# 离散变量分组搜索相关
# discrete_group_num 选填,默认True,使用min_group_num对离散值限制分组数
# discrete_gap_percent 选填,默认True,使用min_gap_percent对离散值限制最小百分比
# discrete_group_percent 选填,默认True,使用min_group_percent对离散值限制最小百分比生成、搜索和过滤的全流程,按顺序概况来说整体经过以下几步:
| 顺序 | 步骤 | 参数 |
|---|---|---|
| 0 | 生成分箱 | 1.自动生成(参考5.2 分箱算法和生成)可通过调参绕开步骤2 - 42.手动指定(参考5.5 手动指定分箱)检测强制跳过步骤 1 - 53.半自动指定(参考5.6 半自动分箱生成)设置 排除项可跳过步骤2 - 4 |
| 1 | 分组数量检测 | min_group_num, discrete_group_num |
| 2-4 | 全量搜索or部分搜索 | find_step_mode, find_step_num |
| 2-4 | 搜索排除项 | keep_separate_value, check_separate_value, check_separate_nearby |
| 2 | 单调性检测 | check_monotonicity, strict_monotonicity, check_ind_monotonicity |
| 3 | 最小占比检测 | min_group_percent, group_include_none, discrete_group_percent |
| 4 | 差异度对比检测 | min_gap_percent, discrete_gap_percent |
| 5 | 取最优结果 | get_cut_by,random_search |
其中1 - 4步骤检测的概述逻辑如下:
| 顺序 | 步骤 | 概述 |
|---|---|---|
| 1 | 分组数量检测 | 检测分箱后的数量是否满足设定的阈值 |
| 2 | 单调性检测 | 检测分箱是否单调,支持V或倒V形状检测 |
| 3 | 最小占比检测 | 检测分箱百分比占比是否满足设定的阈值,支持计算百分比时分母包含或不包含缺失组 |
| 4 | 差异度对比检测 | 检测“分组间命中率差值最小值/整体命中率”是否满足预期 |
这一部分来填上之前章节4 数据过滤和筛选中留下的坑,结合变量评估 - 排除详情来看,如果在搜索中被排除,会添加search: 开头的原因码,比如之前的:
现在就可以解读成指标NAME_HOUSING_TYPE是因为命中discrete_gap_percent离散值最小占比检测而被排除,而merge: 开头的原因码则是提示这个离散值在使用默认算法cumsum合并时因为不满足min_gap_percent而被排除,
一般如果离散值只命中merge: 无法自动合并的话,只要满足离散值检测,如:min_discrete_num、max_discrete_num、discrete_group_percent、discrete_gap_percent等参数判定,还是有机会展示不合并的原始离散值的,
如果在前面5.2 分箱算法和生成部分中的各种算法对比的报告看的足够仔细,还会发现一个细节: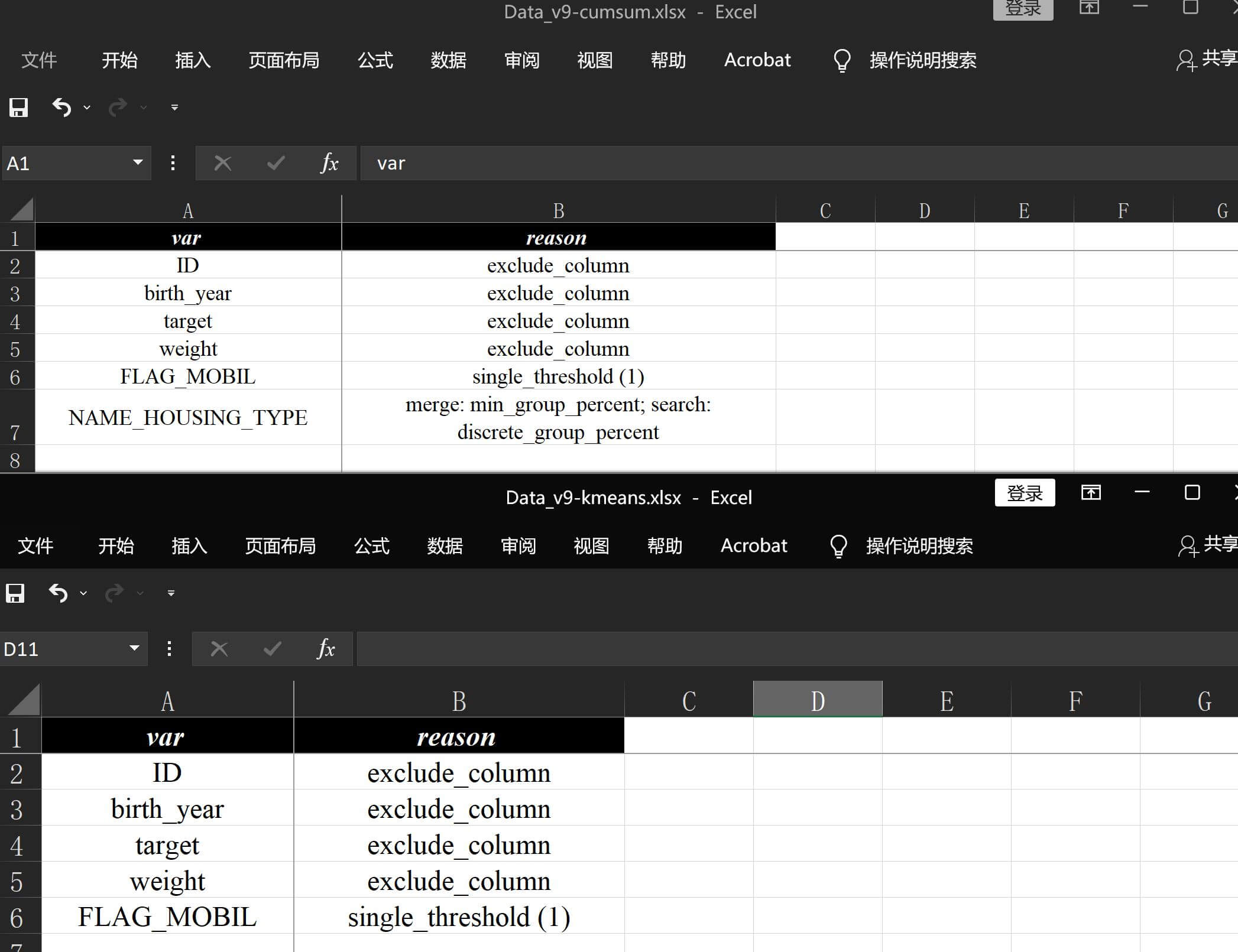
感觉上会很奇怪,为什么kmeans什么都没有排除而cumsum还是排除了NAME_HOUSING_TYPE这个数据项?那先看一下NAME_HOUSING_TYPE这个指标的分布:
从细分示例来看,离散值合并经过woe排序以后再按cumsum合并的逻辑:
cumsum设定的参数max_cut_part默认是10,因此需要按1/10=10%来累进,所以前两组是合并不了的(只有6%+),必须是前三组一档后三组一档,一共分为两组,- 分为两组以后,最后三组
sum的百分比是4.32%,刚好到不了5%,所以会被排除,
但是为什么kmeans可以呢,因为:
kmeans默认开启的supervised_kmeans_cumsum是按min_group_percent对数据进行预先合并,- 前两组
sum后的6%+ > 5%所以前两组可以合并到一起,
最后kmeans算法分组通过检验形成了我们看到的分组结果:
实际百分比计算判定是只算
01占比,需要排除total中2的数量,不过不影响结论就不赘述了,
这个案例非常经典,虽然这个指标没啥效果,但做为算法细节差异来举例说明排除项非常恰当,刚开始选这个数据集的时候也没有想到这么巧,最后来做个调整,基于默认算法cumsum把min_group_percent调整为0试试:
at.Analysis.data_flow(
df_train, "./数据分析demo/v12/v12.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
customized_groups={
"OCCUPATION_TYPE": [
"Cleaning staff|Cooking staff|Drivers|Laborers|Low-skill Laborers|Security staff|Waiters/barmen staff",
"Accountants|Core staff|HR staff|Medicine staff|Private service staff|Realty agents|Sales staff|Secretaries",
"Managers|High skill tech staff|IT staff",
],
"CNT_CHILDREN": [-np.inf, 0, np.inf],
},
exclude_column=["ID", "weight"], # 排除权重
min_group_percent=0,
)可以看到输出文件中数据分析报告v12.xlsx现在就都没有排除项了: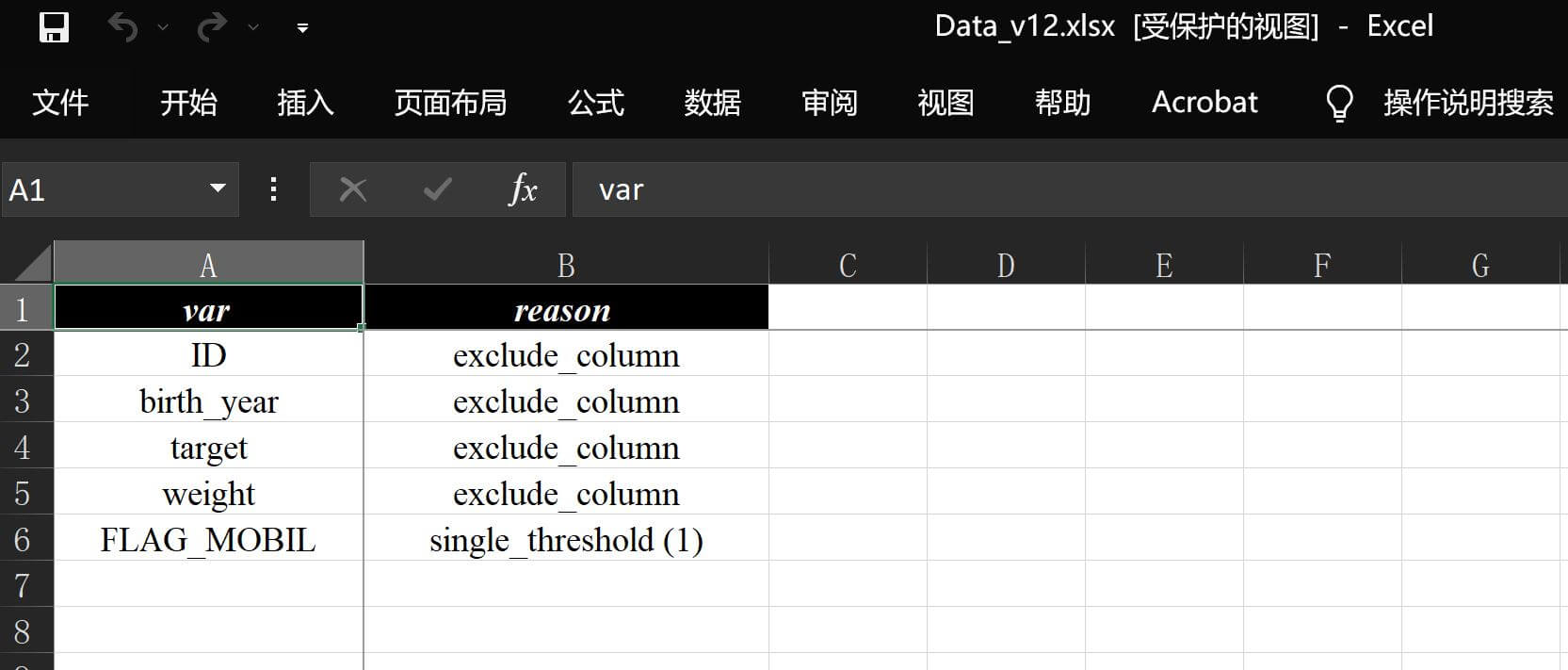
并且占比也是完全符合之前的预判:
5.8 WOE取值优化
这个章节的最后一个环节来简单讲一讲WOE取值的优化,参数如下:
# 分组WOE优化处理相关
# enable_optimal_woe 选填,默认True,启用时会自动对WOE存在的一些特殊情况进行优化
# inf_gap_percent 选填,默认0.3,按已知最大或最小的WOE比例放大,并替换无穷值
# all_inf_replace 选填,默认1,所有WOE都是无穷时的替换项,正负无穷分别加符号
# min_nan_percent 选填,默认0.05,最小接受的缺失组的分组占比,过小时自动填充
# fill_woe_type 选填,默认"avg_all",填充算法,可选"avg_var"取其算术平均
# fill_inf_nan 选填,默认True,min_nan_percent是否对值为无穷的WOE填充
# zero_woe_nan 选填,默认True,将出现的WOE包含缺失值的分组的值替换为0这个部分处理一些特殊情况下的woe优化方式,这个示例数据集不一定能触发这些情况,就不做案例展示了,这里主要放一些优化的场景示例:
inf_gap_percent:某些分组可能样本极不均衡,导致woe为inf(使用已知最接近的woe推算缩放处理)all_inf_replace:数据问题导致预测完美分离,所有woe都是inf(如本文中的weight,一般是需要处理数据的,默认替换成+-1)min_nan_percent:缺失单独一组时占比过小,导致计算的woe可能不具代表性(默认阈值0.05,满足则可选替换为指定值)zero_woe_nan:指定单独一组时区间打空,导致部分woe为缺失(默认采用0填充,其实需要处理数据)fill_woe_type:指定woe的填充值计算方式(默认按woe公式计算0为标准均值,也可以算数平均数),同时应用于min_nan_percent和test_data数据分箱匹配失败时fill_inf_nan:是否将缺失组woe为inf的值按fill_woe_type进行填充,不填充时inf也会被inf_gap_percent处理
6 报告和数据输出
6.1 报告格式调整
输出文档数据分析报告v12.xlsx中的大量格式和颜色都是可以进行修改的,涉及到的自动格式调整参数如下:
# 自动格式调整
# add_excel_table_dir 选填,默认True,给输出的excel表格自动添加目录
# train_test_dir_cn 选填,默认None,即["开发", "验证"],train和test中文
# deal_unused_input 选填,默认"error",处理无效入参的方式,可选"warning"
# text_wrap_trigger 选填,默认36,在auto_formatting时对超过长度的单元格自动换行
# auto_formatting 选填,默认True,自动添加条件格式、设置单元格格式、添加表头格式
# data_bar_cols 选填,默认["rate", "woe", "corr"],条件格式的列,支持str或list
# format_header 选填,默认True,自定义输出表的表头格式,参数通过查看__header__来更改
# hidden_tables 选填,默认None,自定义输出文件中,需要隐藏的表格的名称,支持str或list
# hidden_cols 选填,默认["var_name", "var_new"],输出多表格时自动隐藏的列,支持str或list主要包含:自动目录添加、入参校验、自动条件格式、长文本自动换行,自动单元格格式、自动生成数据栏、自动隐藏不必要的表和列等,
同时也支持手动修改默认表格输出的参数,默认参数在at.dt.__excel__这个位置可见:
正常情况下无需修改,如无必要不建议修改,不恰当的入参可能会引发意料之外的报错
6.2 数据文件输出
除了输出xlsx报告外,还有可能会同时输出pkl和csv等文件,涉及的参数如下:
# 基础定义
# flow_data_type 选填,默认"WOE_",可选"ORI_",输出的数据类型
# auto_set_save_by_flow 选填,默认True,根据flow_data_type来调整save_ori和save_woe_data等
# 输出相关
# save_or_return 选填,默认True,False时会缓存在dt.__data__对应的区域
# 数据存储相关
# save_ori 选填,默认False,True时存储原始数据
# save_json 选填,默认True,将计算结果配置文件输出为json
# save_one_hot 选填,默认False,是否存储数据的独热编码的结果
# save_woe_data 选填,默认True,是否保存筛选后匹配的woe和区间
# save_data_pkl 选填,默认True,将训练数据的计算结果存储为pkl文件
# save_raw_dataframe 选填,默认False,输出输入数据的筛选原始数据到csv文件默认配置会输出包含woe信息的csv文件,主要包含woe取值和woe分箱,add_info指定的列也会在其中保留,比如之前的数据分析报告v12.xlsx生成会同时输出csv和json等文件: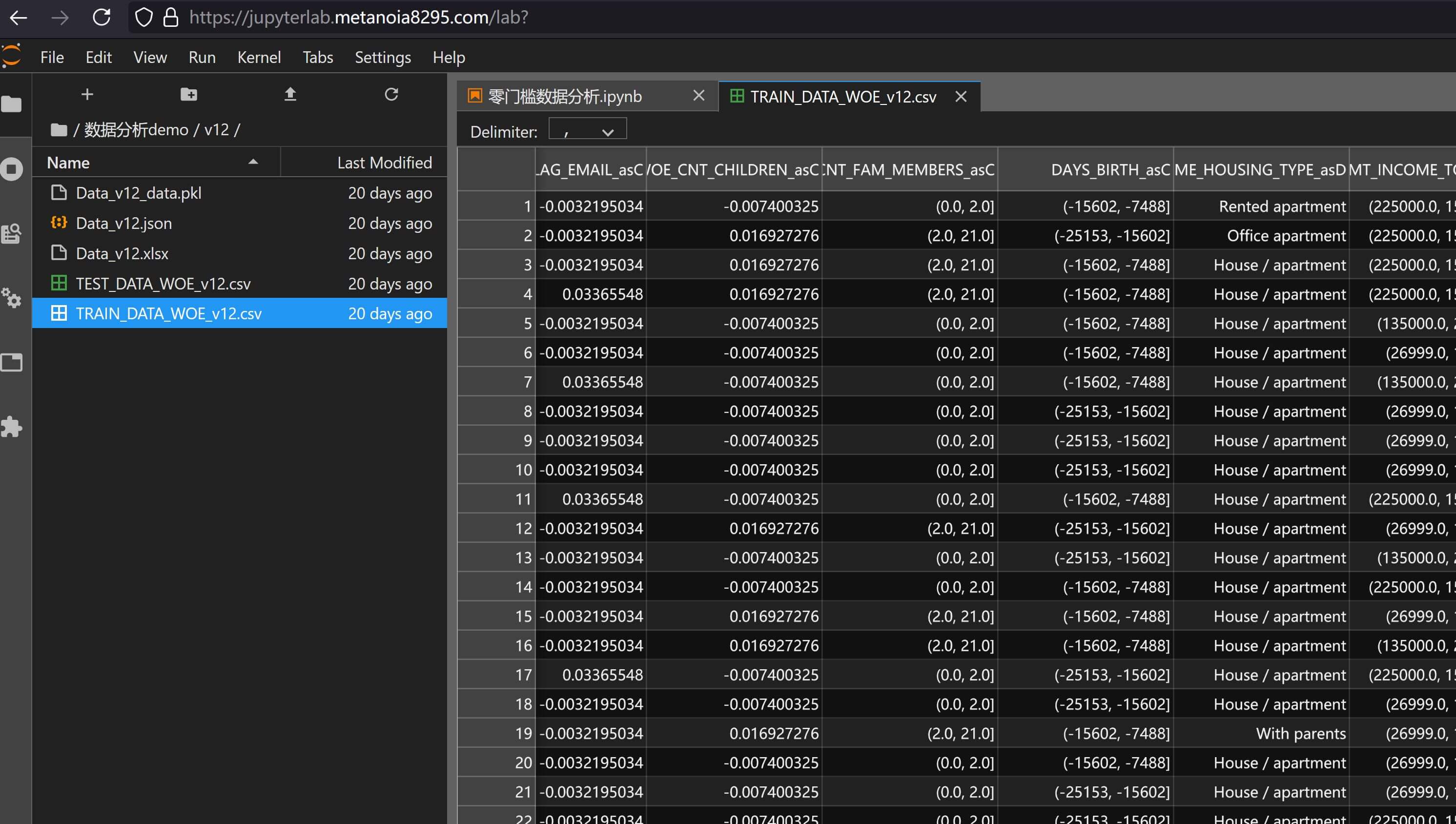
WOE)
当需要存储原始输入的数据时,可以开启save_raw_dataframe,例如输入:
at.Analysis.data_flow(
df_train, "./数据分析demo/v12-raw/v12-raw.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
customized_groups={
"OCCUPATION_TYPE": [
"Cleaning staff|Cooking staff|Drivers|Laborers|Low-skill Laborers|Security staff|Waiters/barmen staff",
"Accountants|Core staff|HR staff|Medicine staff|Private service staff|Realty agents|Sales staff|Secretaries",
"Managers|High skill tech staff|IT staff",
],
"CNT_CHILDREN": [-np.inf, 0, np.inf],
},
exclude_column=["ID", "weight"], # 排除权重
min_group_percent=0,
save_raw_dataframe=True,
)则能在输出中看到原始输入的指标形成的csv文件: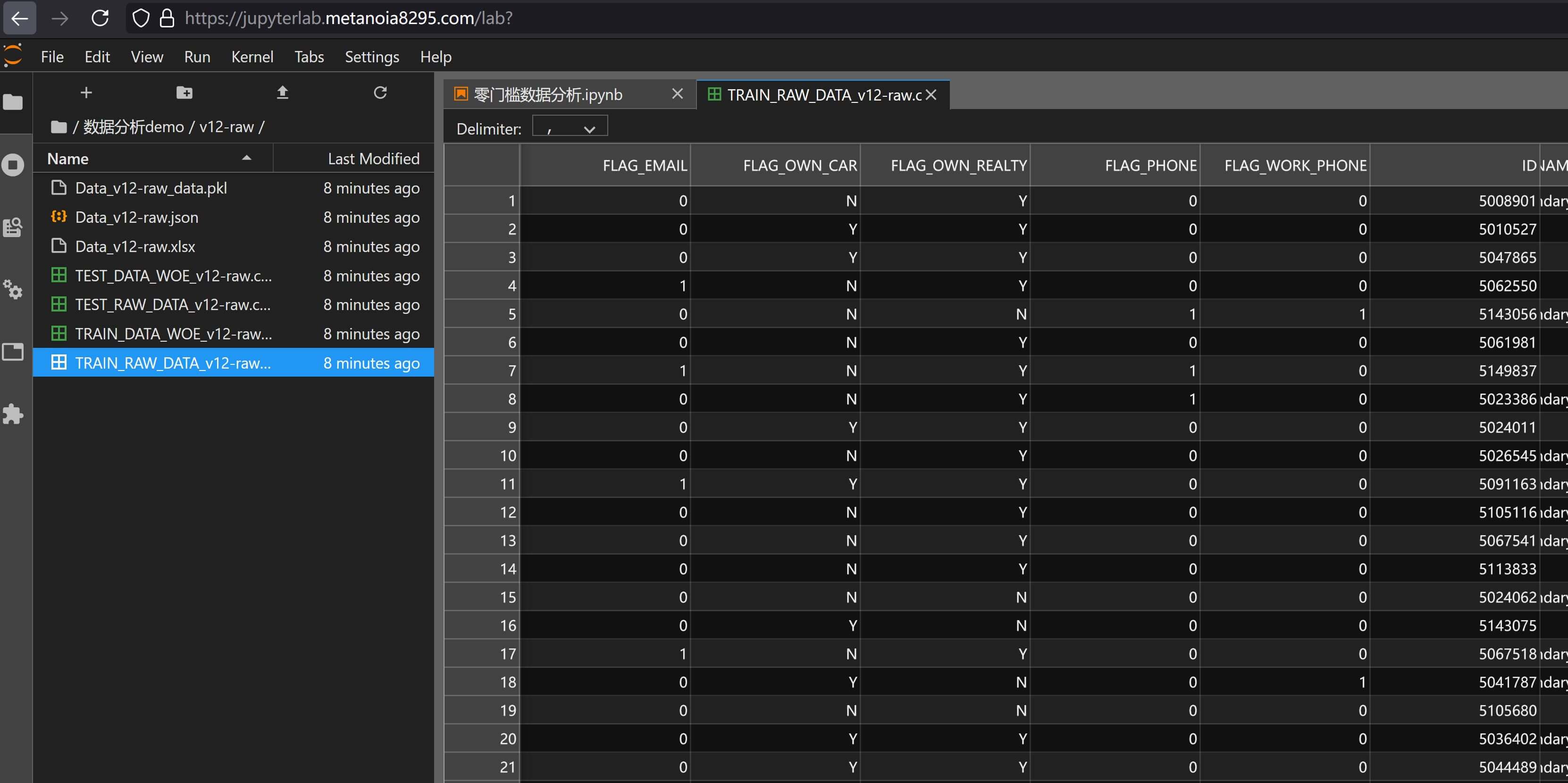
如果表太大,则输出的woe写成文件时io会较为费时,可以考虑使用参数save_or_return来实现内存输出避免重复io读写,例如输入:
at.Analysis.data_flow(
df_train, "./数据分析demo/v12-return/v12-return.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
customized_groups={
"OCCUPATION_TYPE": [
"Cleaning staff|Cooking staff|Drivers|Laborers|Low-skill Laborers|Security staff|Waiters/barmen staff",
"Accountants|Core staff|HR staff|Medicine staff|Private service staff|Realty agents|Sales staff|Secretaries",
"Managers|High skill tech staff|IT staff",
],
"CNT_CHILDREN": [-np.inf, 0, np.inf],
},
exclude_column=["ID", "weight"], # 排除权重
min_group_percent=0,
save_or_return=False,
)就可以在内存的__data__位置中看到woe的dataframe对象: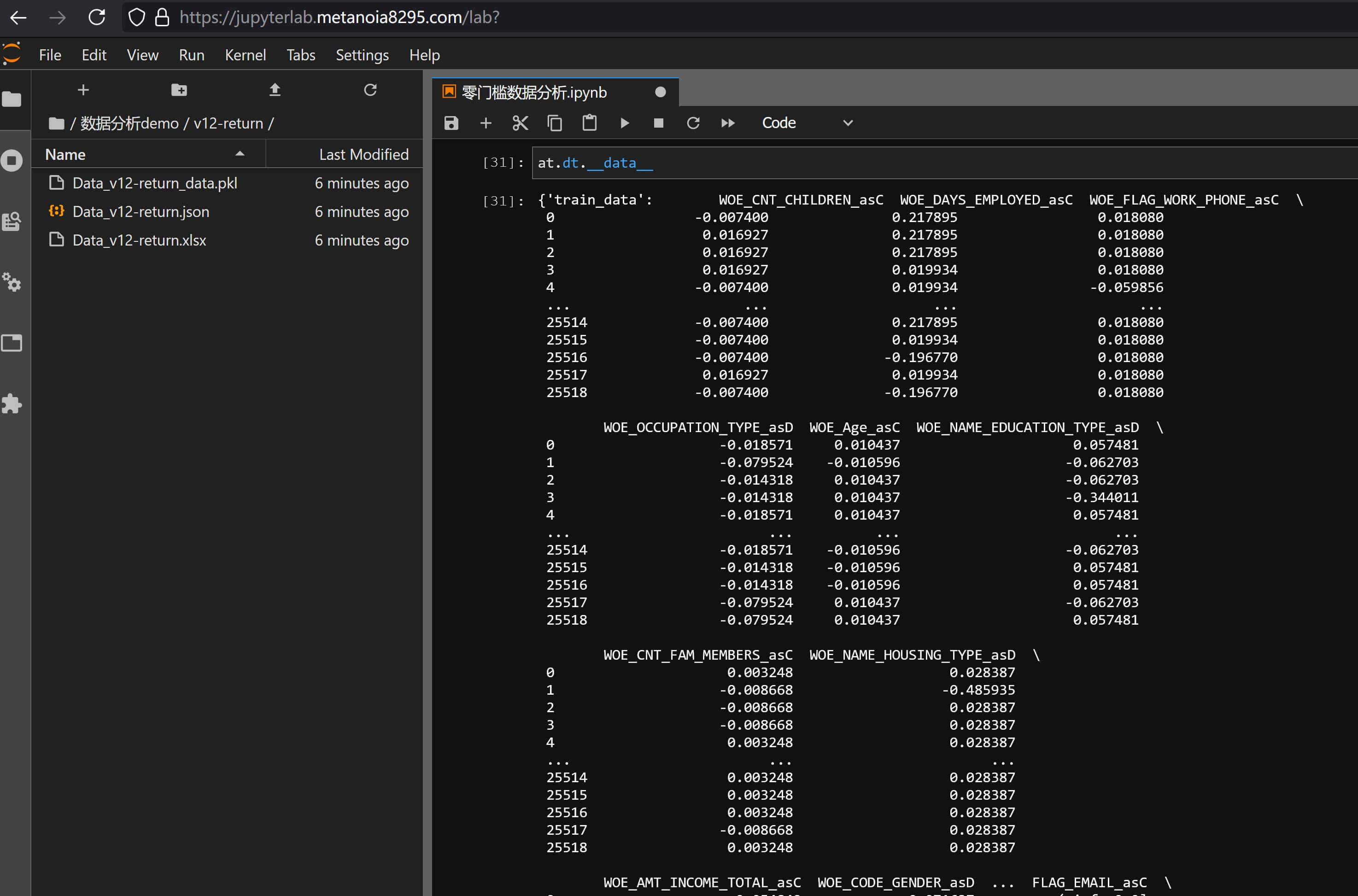
除了woe和原始值输出,最后介绍一下预处理数据输出,使用参数flow_data_type或save_ori来输出经过2.2 数据预处理后的数据,同时这种情况下corr的计算也是基于预处理的数据进行的,比如:
at.Analysis.data_flow(
df_train, "./数据分析demo/v12-ori/v12-ori.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
customized_groups={
"OCCUPATION_TYPE": [
"Cleaning staff|Cooking staff|Drivers|Laborers|Low-skill Laborers|Security staff|Waiters/barmen staff",
"Accountants|Core staff|HR staff|Medicine staff|Private service staff|Realty agents|Sales staff|Secretaries",
"Managers|High skill tech staff|IT staff",
],
"CNT_CHILDREN": [-np.inf, 0, np.inf],
},
exclude_column=["ID", "weight"], # 排除权重
min_group_percent=0,
save_ori=True, replace_option={"num_replace": {0: -999}}
)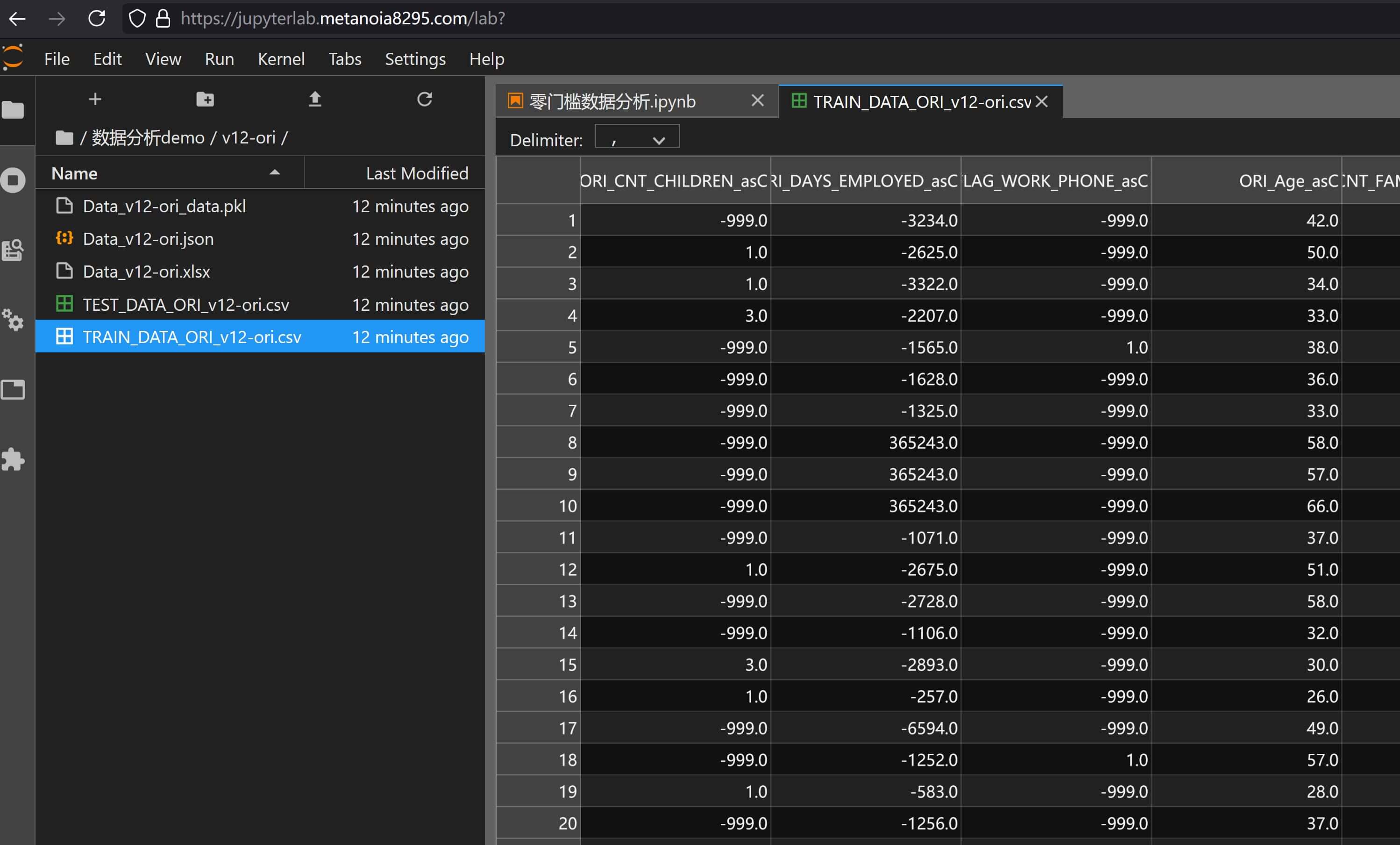
可以看到输出csv文件中的0替换成了-999,和直接使用save_raw_dataframe还是有一些差异的,应用场景上也有差异,
最后我们把上述几个案例的数据进行打包汇总,我这里使用自定义函数zip_dir_files进行文件夹自动打包(就是zip压缩):
具体的压缩包文件可以从下面的链接下载:
6.3 配置映射和还原
除了常规输出的csv和xlsx文件外,还会输出配置文件json和pkl,用来避免配置文件的重复输入,涉及的主要参数有:
# 从配置文件还原
# recover_from_json 选填,默认None,输入对应的.json文件来从对应的json映射结果
# recover_from_pkl 选填,默认True,默认从pkl完整映射上次计算结果,overwrite时失效
# overwrite_json 选填,默认False,使运行时的入参设置覆盖读取的json文件的对应设置例如之前数据分析报告v12.xlsx搭配的配置文件有Data_v12.json和Data_v12_data.pkl,如果打开可以看到里面主要都是之前定义的参数和分析过程中的缓存对象:
配置文件的主要使用方式举例如下:
at.Analysis.data_flow(
df_train, "./数据分析demo/v12-rec/v12-rec.xlsx", test_data=df_test,
recover_from_json="./数据分析demo/v12/Data_v12.json"
)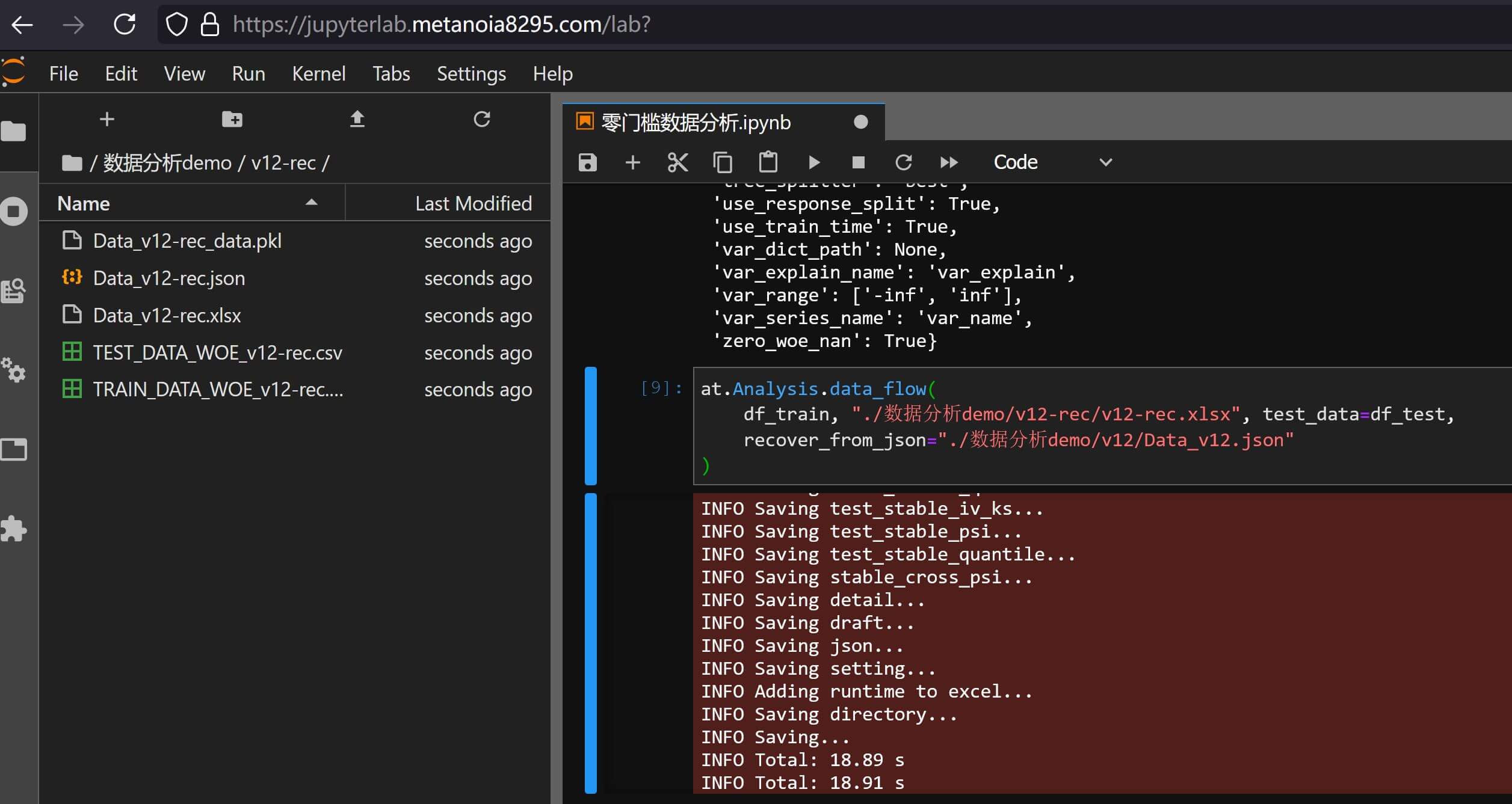
从结果文件数据分析报告v12-rec.xlsx来看,和之前数据分析报告v12.xlsx效果相同的情况下,节省了很多笔墨
- 参数
recover_from_pkl用在仅100%恢复之前的配置文件,且不进行覆写调整的场景下使用 - 有效使用
recover_from_pkl时,不再会经过判断和过滤,因此不生成变量评估 - 排除详情页面 - 如果需要基于配置文件进行调整,不建议修改
json文件(可能会打破json与pkl文件之间的数据关联),推荐直接入参需要调整的参数 - 只要覆写入参和之前不同,就会自动启用
overwrite_json,但只有当判定覆写入参影响训练结果时,才会自动禁用recover_from_pkl,此时并非100%还原历史数据,而是基于当下数据和历史配置重新训练 - 当
overwrite_json的对象为list时,且入参为"add_info"或"node_info"时,会对参数进行合并去重而不是覆写 - 当
overwrite_json的对象为dict时,进行update操作而不是覆写 - 一开始自定义的
customized_groups除非入参覆盖不然都会还原,由算法生成入参的customized_groups会在判定覆写入参影响训练结果时被替换为重新训练以后的值
6.4 多数据映射和还原
在上面6.3 配置映射和还原这节中介绍了配置文件的还原,但是如2.5 多数据映射所述,现实使用时情况会比较复杂,这里再介绍一下多数据映射情况下的还原方式,主要参数如下:
# alpha_tools.Analysis参数
# recover_path 选填,默认None,入参str需要以.xlsx结尾,根据输出文件还原json和pkl配置
# recover_search 选填,默认True,按train_name和test_names入参联动调整recover_path路径取值
# only_recover_json 选填,默认False,在使用recover_path还原时是否忽略pkl,只按json文件还原配置这里来看一个稍微复杂的案例,其中output_name2处与直接修改5.7 分箱搜索和过滤处的cut_method入参效果相同:
# 使用ori_name配置映射到output_name1
# 再使用output_name1配置映射到output_name2(这一步train_name&test_names需要1&2一致)
ori_name = "./数据分析demo/v12/v12.xlsx"
output_name1 = "./数据分析demo/v12-rec-more/v12-one.xlsx"
output_name2 = "./数据分析demo/v12-rec-more/v12-other.xlsx"
# 按配置历史数据100%还原
at.Analysis.data_flow(
df_train, output_name1,
test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"],
recover_path=ori_name
)
# 继承配置并按"tree"重新训练
at.Analysis.data_flow(
df_train, output_name2,
test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"],
recover_path=output_name1, cut_method="tree"
)
# 打包结果
at.dt.Api.zip_dir_files("./数据分析demo/v12-rec-more.zip", "./数据分析demo/v12-rec-more")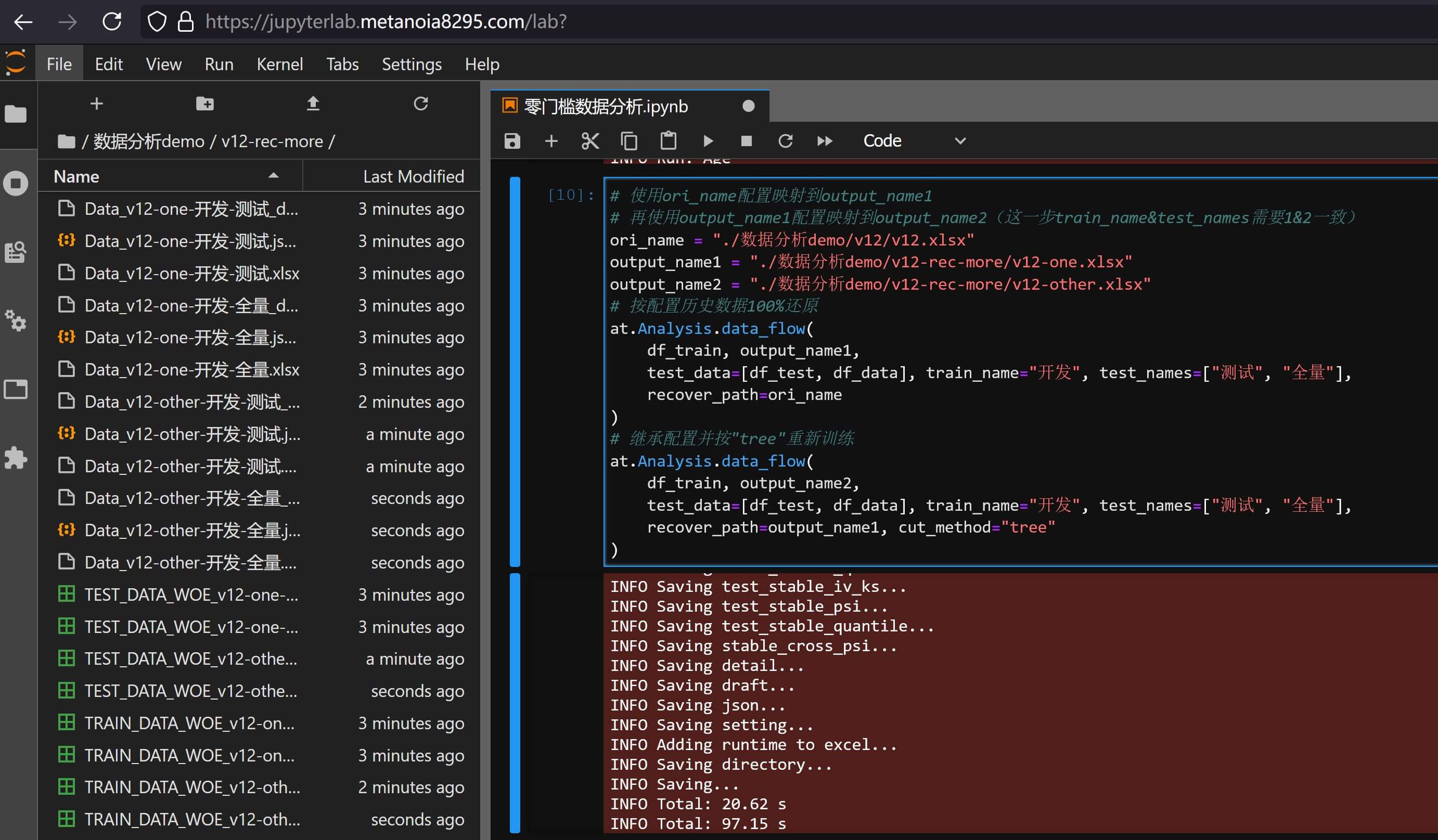
这样就实现了多文件的映射与还原,打包文件详情可以自行下载v12-rec-more.zip查看
6.5 报告合并与数据合并
在上面5.2 分箱算法和生成这节中,我们看到很多时候是需要横向对比多个报告的,因此存在针对多份报告和数据进行自动合并的需求,实现了既可以合并报告内的页面,也可以将各个分析的数据集移动并重命名到同一路径,主要通过以下两个函数实现: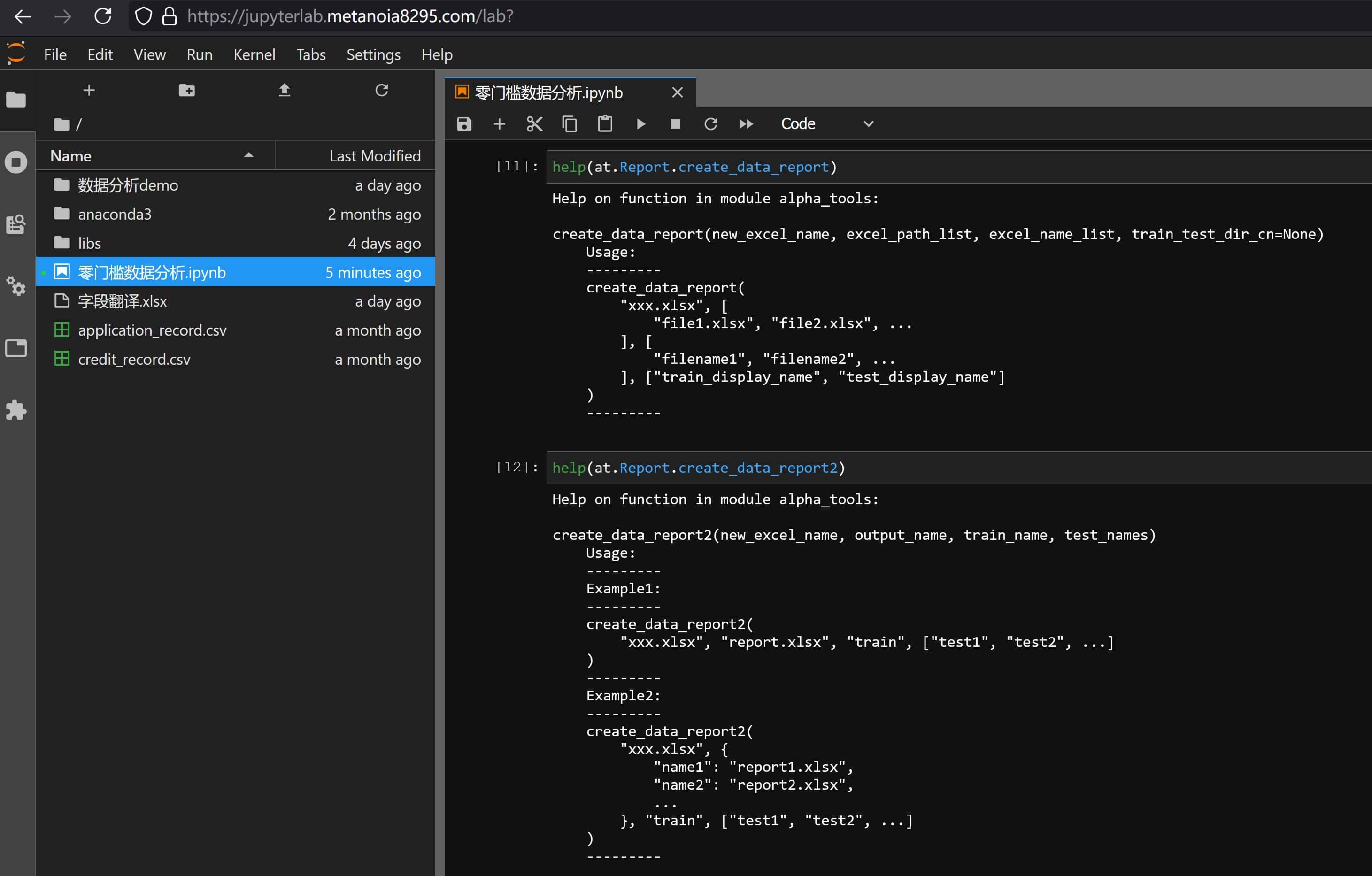
横向合并需要手动指定,比如之前5.2 分箱算法和生成这节中使用方式为:
at.Report.create_data_report(
"./数据分析demo/v9-算法对比/v9-算法对比.xlsx", [
"./数据分析demo/v9-cumsum/v9-cumsum.xlsx", "./数据分析demo/v9-quantile/v9-quantile.xlsx",
"./数据分析demo/v9-linspace/v9-linspace.xlsx", "./数据分析demo/v9-kmeans/v9-kmeans.xlsx",
"./数据分析demo/v9-bestks/v9-bestks.xlsx", "./数据分析demo/v9-tree/v9-tree.xlsx",
"./数据分析demo/v9-chimerge/v9-chimerge.xlsx", "./数据分析demo/v9-ratemerge/v9-ratemerge.xlsx"
], ["cumsum", "quantile", "linspace", "kmeans", "bestks", "tree", "chimerge", "ratemerge"]
)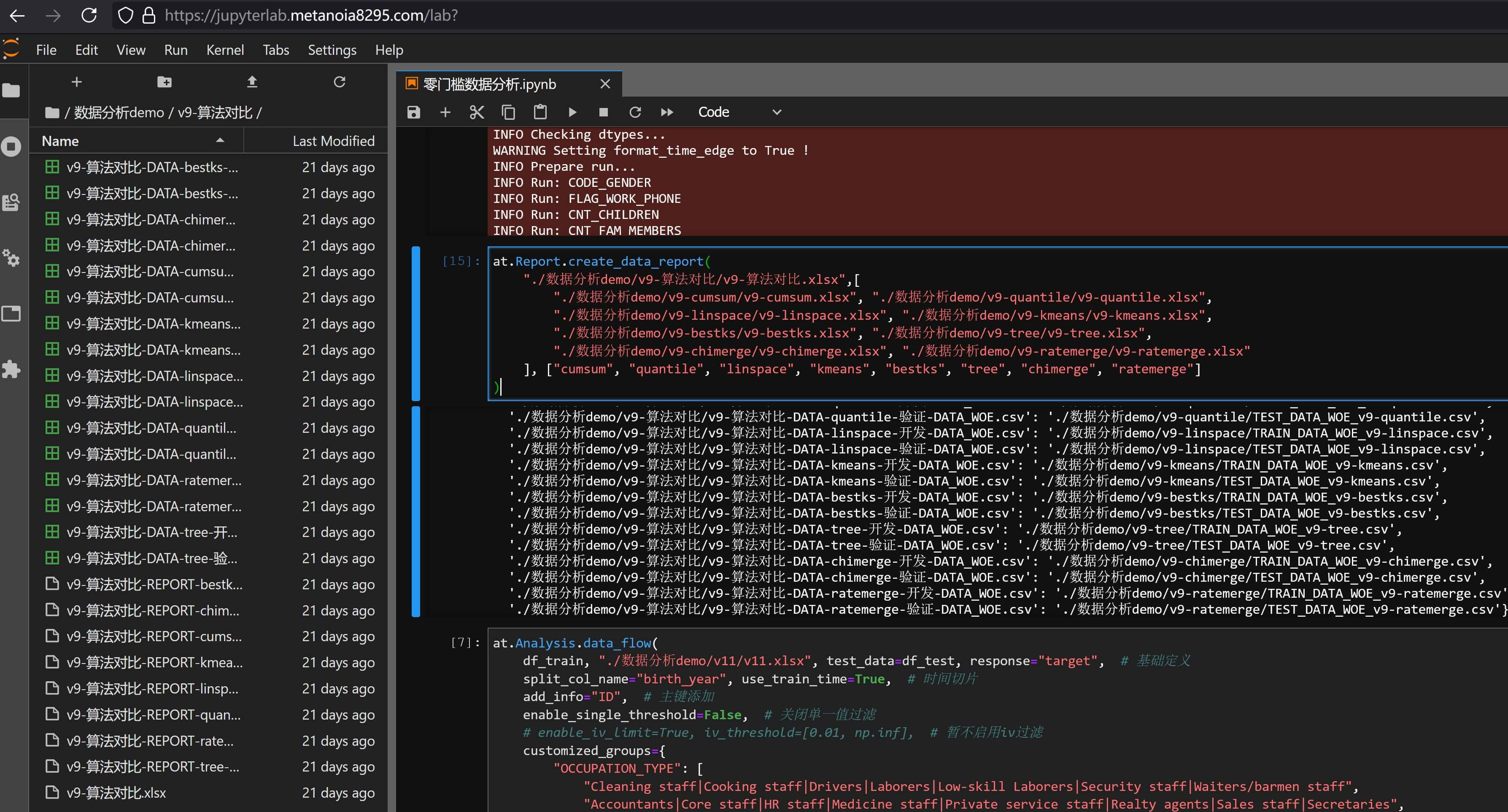
最后得到的效果和对应的分析,也在5.2 分箱算法和生成这节中有所展示:DAYS_EMPLOYED、OCCUPATION_TYPE)
而针对2.5 多数据映射和6.4 多数据映射和还原中提到的多数据情况,需要进行纵向合并,简单输入:
at.Report.create_data_report2(
"./数据分析demo/v12-纵向合并/v12-纵向合并.xlsx", "./数据分析demo/v12-rec-more/v12-one.xlsx",
train_name="开发", test_names=["测试", "全量"]
)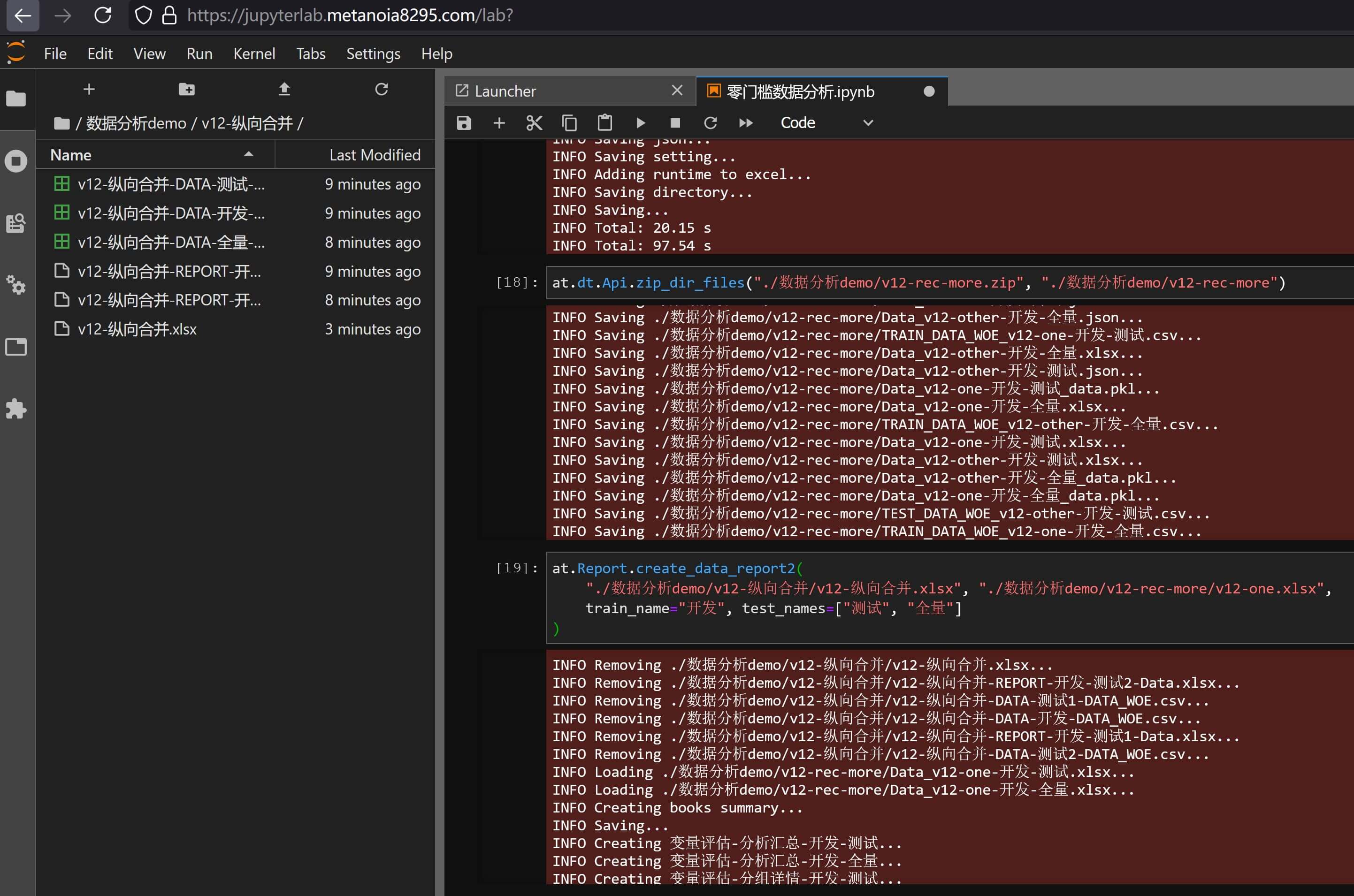
即可实现多数据映射层面的纵向文件合并,效果如下: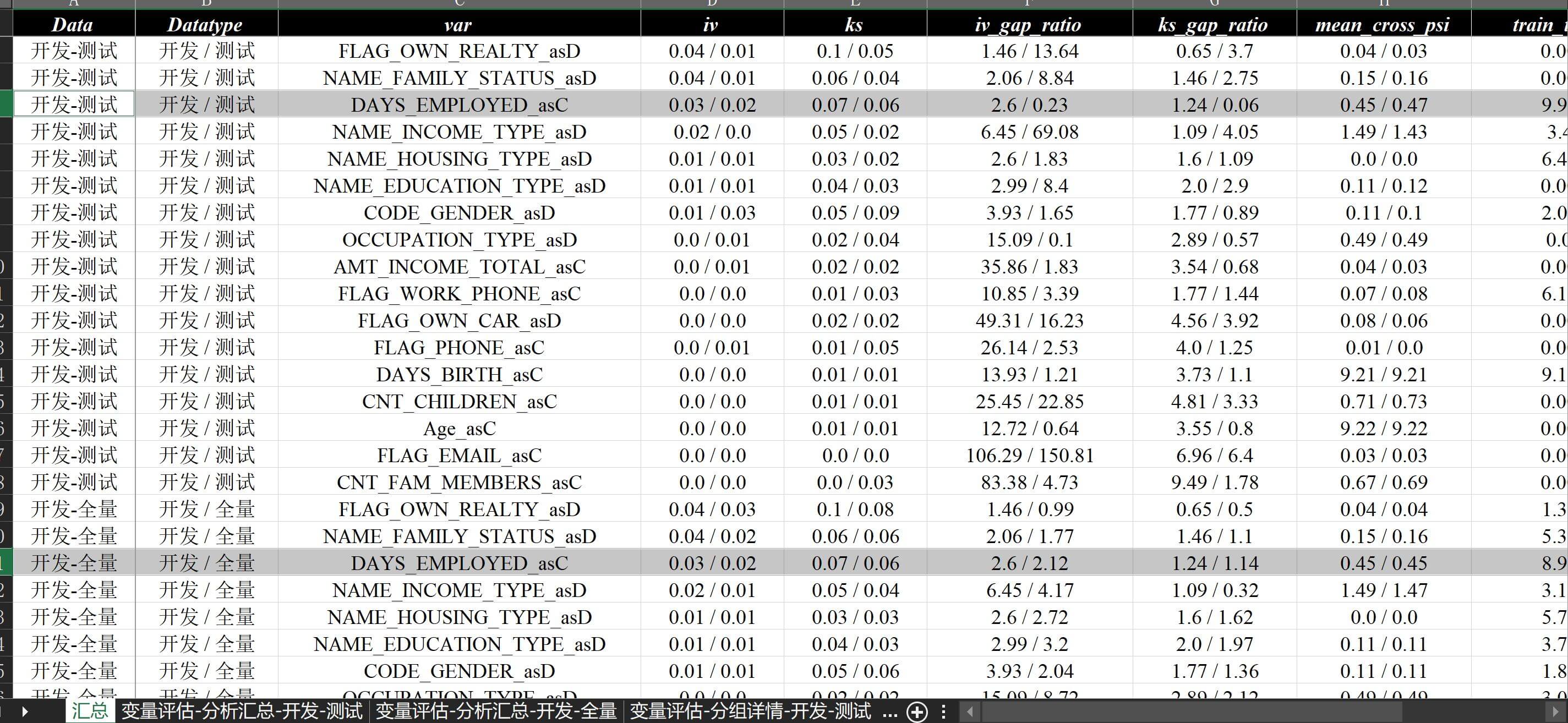
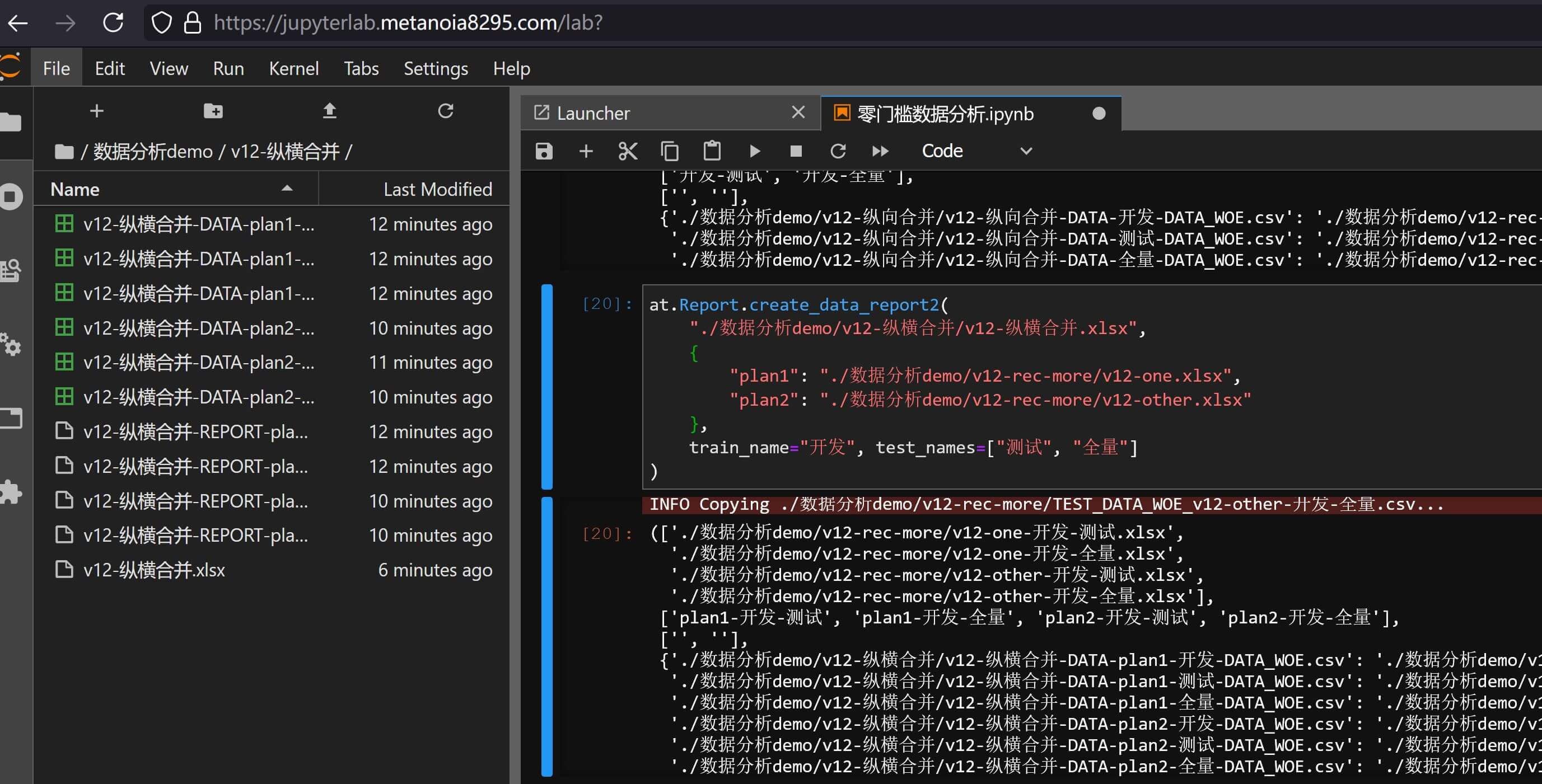
另外如果涉及到横向合并多个纵向数据集的报告,则可输入:
at.Report.create_data_report2(
"./数据分析demo/v12-纵横合并/v12-纵横合并.xlsx",
{
"plan1": "./数据分析demo/v12-rec-more/v12-one.xlsx",
"plan2": "./数据分析demo/v12-rec-more/v12-other.xlsx"
},
train_name="开发", test_names=["测试", "全量"]
)
实现多方案多数据集综合交叉对比,排序后的效果截图如下: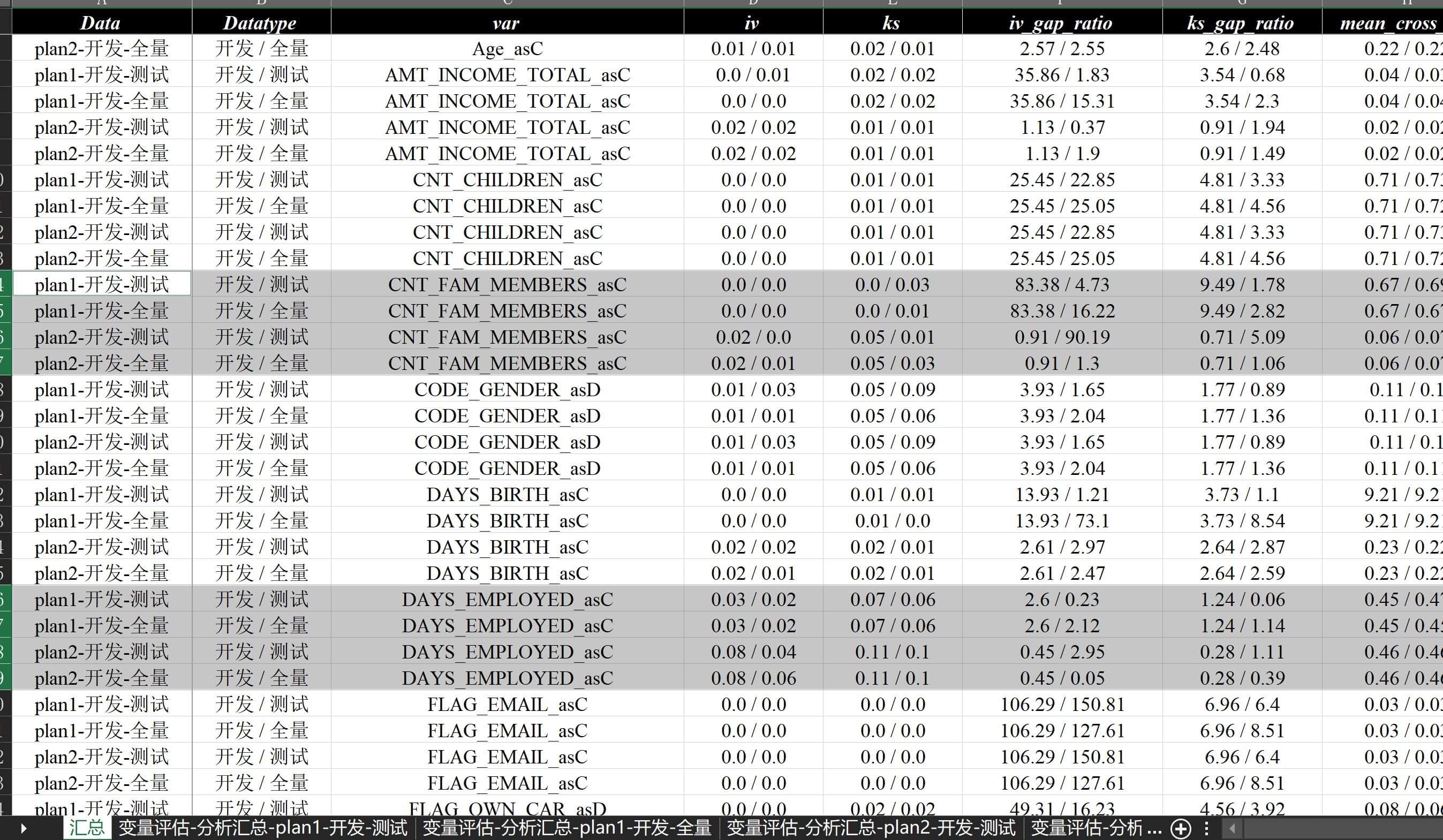
简单来看,部分数据上tree算法还是有些许提升效果的,
报告合并的
sheetname范围和csv搜索的范围均在在__excel__中定义如果是在
win环境下,会多一页附录,原理是使用pywin32调用excel把文件做为附件插入
windows)最后附上以上三类报告合并的样例文件:
7 总结
全文完整的工作簿可自行下载:零门槛数据分析.ipynb,也可以点击查看我转化好的html文档:零门槛数据分析.html,
装好依赖如
pip install jupyter_contrib_nbextensions等后,命令行运行jupyter nbconvert --to html xxx.ipynb即可生成html文档,注意替换xxx.ipynb为需要转换的文件名默认生成的
html是不支持自动滚动的,编辑html中的.jp-OutputArea-output部分,注释两行,新增两行,修改成如下即可:.jp-OutputArea-output { max-height: 300px; overflow: scroll; /** height: auto; overflow: auto; */ user-select: text; -moz-user-select: text; -webkit-user-select: text; -ms-user-select: text; }有些较新版本可能改了没效果,可以尝试搜索
.jp-OutputArea-output pre部分,并插入上述的两行:.jp-OutputArea-output pre { line-height: inherit; font-family: inherit; max-height: 300px; overflow: scroll; }
下面把案例涉及的主要代码汇总梳理一下,首先是模块和数据导入:
import pandas as pd
# 导入我自定义的模块
import sys
sys.path.append("./code_libs")
import alpha_tools as at
# 导入数据
df_ = pd.read_csv("application_record.csv")
df_response = pd.read_csv("credit_record.csv")然后是数据定义和划分:
# 添加“年龄”变量
df_['Age'] = -(df_['DAYS_BIRTH']) // 365
# 定义标签和数据
df_["target"] = df_["ID"].map(df_response.groupby("ID")["STATUS"].apply(
lambda x: 1 if ({"2", "3", "4", "5"} & set(x)) else 2 if ({"1"} & set(x)) else 0))
df_['birth_year'] = df_["Age"].map(lambda x: str(2021 - x) + "0101")
# 添加权重
df_["weight"] = df_["target"].map(lambda x: 2 if x == 1 else 1)
df_data = df_[df_["target"].notnull()]
# 划分数据集
from sklearn.model_selection import train_test_split
df_train, df_test = train_test_split(
df_data, test_size=0.3, stratify=df_data["target"], random_state=42)然后是主要的入参分析:
at.Analysis.data_flow(
df_train, "./数据分析demo/v12/v12.xlsx", test_data=df_test, response="target", # 基础定义
split_col_name="birth_year", use_train_time=True, # 时间切片
add_info="ID", # 主键添加
enable_single_threshold=False, # 关闭单一值过滤
# enable_iv_limit=True, iv_threshold=[0.01, np.inf], # 暂不启用iv过滤
customized_groups={
"OCCUPATION_TYPE": [
"Cleaning staff|Cooking staff|Drivers|Laborers|Low-skill Laborers|Security staff|Waiters/barmen staff",
"Accountants|Core staff|HR staff|Medicine staff|Private service staff|Realty agents|Sales staff|Secretaries",
"Managers|High skill tech staff|IT staff",
],
"CNT_CHILDREN": [-np.inf, 0, np.inf],
},
exclude_column=["ID", "weight"], # 排除权重
min_group_percent=0,
)继续基于分析的配置进行映射和修改:
# 使用ori_name配置映射到output_name1
# 再使用output_name1配置映射到output_name2(这一步train_name&test_names需要1&2一致)
ori_name = "./数据分析demo/v12/v12.xlsx"
output_name1 = "./数据分析demo/v12-rec-more/v12-one.xlsx"
output_name2 = "./数据分析demo/v12-rec-more/v12-other.xlsx"
# 按配置历史数据100%还原
at.Analysis.data_flow(
df_train, output_name1,
test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"],
recover_path=ori_name
)
# 继承配置并按"tree"重新训练
at.Analysis.data_flow(
df_train, output_name2,
test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"],
recover_path=output_name1, cut_method="tree"
)最后是基于分析形成对比报告:
at.Report.create_data_report2(
"./数据分析demo/v12-纵横合并/v12-纵横合并.xlsx",
{
"plan1": "./数据分析demo/v12-rec-more/v12-one.xlsx",
"plan2": "./数据分析demo/v12-rec-more/v12-other.xlsx"
},
train_name="开发", test_names=["测试", "全量"]
)至此完成了这个模块主要涉及的分析,算上注释所有的代码行数大约是60行,整体还是符合零基础的门槛的,有兴趣进一步联系可邮件或留言咨询